

Ubuntu 20.04 Hadoop

- 1714
- 57
- Miss Angelo Toy
Apache Hadoop terdiri dari beberapa paket perangkat lunak open source yang bekerja bersama untuk penyimpanan terdistribusi dan pemrosesan data besar terdistribusi. Ada empat komponen utama untuk Hadoop:
- Hadoop Common - berbagai pustaka perangkat lunak yang diandalkan Hadoop untuk dijalankan
- Sistem File Terdistribusi Hadoop (HDFS) - Sistem file yang memungkinkan distribusi dan penyimpanan data besar yang efisien di seluruh sekelompok komputer
- Hadoop MapReduce - digunakan untuk memproses data
- Benang Hadoop - API yang mengelola alokasi sumber daya komputasi untuk seluruh cluster
Dalam tutorial ini, kami akan membahas langkah -langkah untuk menginstal Hadoop Versi 3 di Ubuntu 20.04. Ini akan melibatkan pemasangan HDFS (namenode dan data), benang, dan mapreduce pada satu node cluster yang dikonfigurasi dalam mode terdistribusi semu, yang merupakan simulasi terdistribusi pada mesin tunggal. Setiap komponen Hadoop (HDFS, Benang, MapReduce) akan berjalan pada simpul kami sebagai proses Java yang terpisah.
Dalam tutorial ini Anda akan belajar:
- Cara Menambahkan Pengguna untuk Lingkungan Hadoop
- Cara menginstal prasyarat java
- Cara mengkonfigurasi ssh tanpa kata sandi
- Cara menginstal hadoop dan mengkonfigurasi file xml terkait yang diperlukan
- Cara Memulai Cluster Hadoop
- Cara Mengakses Namenode dan Web UI Web ResourceManager
Apache Hadoop di Ubuntu 20.04 FOSSA FOCAL | Kategori | Persyaratan, konvensi atau versi perangkat lunak yang digunakan |
|---|---|
| Sistem | Dipasang Ubuntu 20.04 atau Ubuntu yang ditingkatkan.04 FOSSA FOCAL |
| Perangkat lunak | Apache Hadoop, Java |
| Lainnya | Akses istimewa ke sistem Linux Anda sebagai root atau melalui sudo memerintah. |
| Konvensi | # - mensyaratkan perintah linux yang diberikan untuk dieksekusi dengan hak istimewa root baik secara langsung sebagai pengguna root atau dengan menggunakan sudo memerintah$ - mensyaratkan perintah Linux yang diberikan untuk dieksekusi sebagai pengguna biasa |
Buat Pengguna untuk Lingkungan Hadoop
Hadoop harus memiliki akun pengguna khusus di sistem Anda. Untuk membuat satu, buka terminal dan ketik perintah berikut. Anda juga akan diminta untuk membuat kata sandi untuk akun tersebut.
$ sudo adduser hadoop
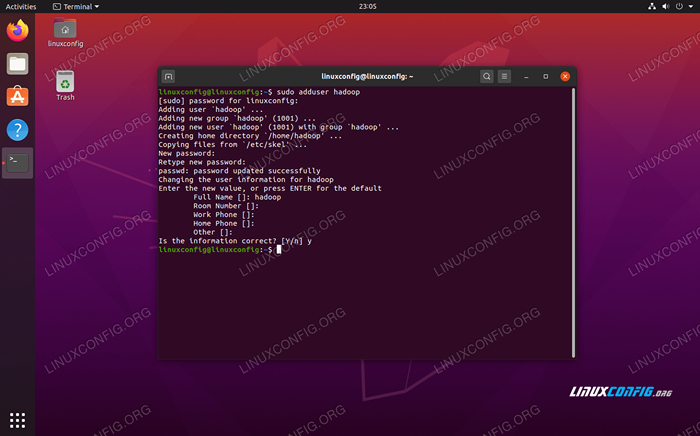 Buat Pengguna Hadoop Baru
Buat Pengguna Hadoop Baru Instal Prasyarat Java
Hadoop didasarkan pada java, jadi Anda harus menginstalnya di sistem Anda sebelum dapat menggunakan Hadoop. Pada saat penulisan ini, Hadoop Versi 3 saat ini.1.3 Membutuhkan Java 8, jadi itulah yang akan kami pasang di sistem kami.
Gunakan dua perintah berikut untuk mengambil daftar paket terbaru tepat dan instal Java 8:
$ sudo apt update $ sudo apt menginstal openjdk-8-jdk openjdk-8-jre
Konfigurasikan SSH tanpa kata sandi
Hadoop bergantung pada SSH untuk mengakses nodenya. Ini akan terhubung ke mesin jarak jauh melalui SSH serta mesin lokal Anda jika Anda memiliki Hadoop berjalan di atasnya. Jadi, meskipun kami hanya menyiapkan Hadoop di mesin lokal kami di tutorial ini, kami masih perlu menginstal SSH. Kami juga harus mengkonfigurasi SSH tanpa kata sandi
sehingga Hadoop dapat diam -diam membuat koneksi di latar belakang.
- Kita akan membutuhkan paket klien server openssh dan openssh. Instal mereka dengan perintah ini:
$ sudo apt instalasi openssh-server openssh-client
- Sebelum melanjutkan lebih jauh, yang terbaik adalah masuk ke
Hadoopakun pengguna yang kami buat sebelumnya. Untuk mengubah pengguna di terminal Anda saat ini, gunakan perintah berikut:$ su hadoop
- Dengan paket -paket yang diinstal, saatnya untuk menghasilkan pasangan kunci publik dan pribadi dengan perintah berikut. Perhatikan bahwa terminal akan meminta Anda beberapa kali, tetapi yang perlu Anda lakukan hanyalah terus memukul
MEMASUKIuntuk melanjutkan.$ ssh -keygen -t RSA
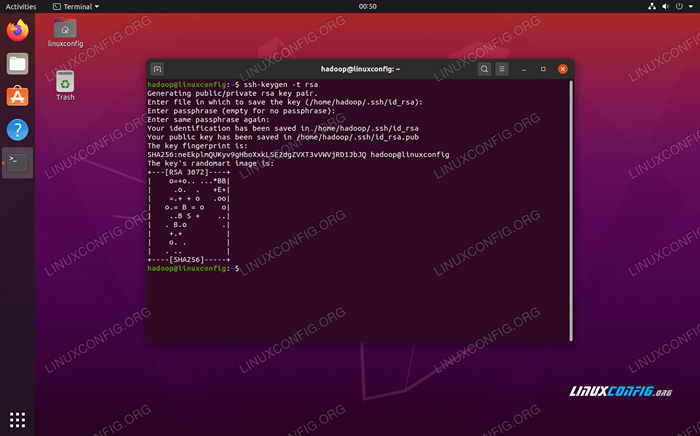 Menghasilkan kunci RSA untuk SSH tanpa kata sandi
Menghasilkan kunci RSA untuk SSH tanpa kata sandi - Selanjutnya, salin kunci RSA yang baru dihasilkan
id_rsa.pubkeotorisasi_keys:$ kucing ~/.ssh/id_rsa.pub >> ~//.ssh/otorisasi_keys
- Anda dapat memastikan bahwa konfigurasi berhasil dengan sshing ke localhost. Jika Anda dapat melakukannya tanpa diminta untuk kata sandi, Anda siap melakukannya.
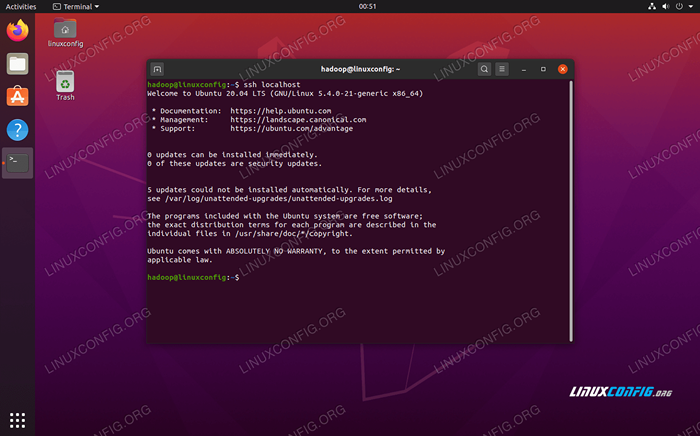 Sshing ke dalam sistem tanpa diminta untuk kata sandi berarti itu berhasil
Sshing ke dalam sistem tanpa diminta untuk kata sandi berarti itu berhasil
Instal Hadoop dan konfigurasikan file XML terkait
Buka situs web Apache untuk mengunduh Hadoop. Anda juga dapat menggunakan perintah ini jika Anda ingin mengunduh Hadoop Versi 3.1.3 biner secara langsung:
$ wget https: // unduhan.Apache.org/hadoop/common/hadoop-3.1.3/Hadoop-3.1.3.ter.GZ
Ekstrak unduhan ke Hadoop Direktori Rumah Pengguna dengan perintah ini:
$ tar -xzvf hadoop -3.1.3.ter.GZ -C /HOME /HADOOP
Menyiapkan Variabel Lingkungan
Pengikut ekspor Perintah akan mengonfigurasi variabel lingkungan Hadoop yang diperlukan pada sistem kami. Anda dapat menyalin dan menempelkan semua ini ke terminal Anda (Anda mungkin perlu mengubah baris 1 jika Anda memiliki versi Hadoop yang berbeda):
Ekspor Hadoop_home =/home/hadoop/hadoop-3.1.3 Ekspor Hadoop_install = $ Hadoop_Home Ekspor Hadoop_Mapred_Home = $ Hadoop_Home Ekspor Hadoop_Common_Home = $ Hadoop_Home Ekspor Hadoop_Hdfs_Home = $ hadoop_home $ hadoop = hadoop_home Export hadoOP_HOOP _HOOP ucoOP_HOOP ucoOP = hadoop hadoop_home Hadoop_common quoop_home quoOP ucoop = HadoOP ucoop_home hadoOP_home hadoOP _HOOP_HOOP_HOOP _HOOP _HOOP _HOOP _HOOP _HOOP _HOOP 1 Ekspor Hadoop_opts = "-Djava.perpustakaan.path = $ hadoop_home/lib/asli "Sumber .Bashrc File di sesi login saat ini:
$ sumber ~/.Bashrc
Selanjutnya, kami akan membuat beberapa perubahan pada Hadoop-env.SH file, yang dapat ditemukan di direktori instalasi Hadoop di bawah /etc/hadoop. Gunakan Nano atau editor teks favorit Anda untuk membukanya:
$ nano ~/hadoop-3.1.3/etc/hadoop/hadoop-env.SH
Mengubah Java_home variabel ke tempat java diinstal. Di sistem kami (dan mungkin milik Anda juga, jika Anda menjalankan Ubuntu 20.04 dan telah mengikuti bersama kami sejauh ini), kami mengubah garis itu menjadi:
Ekspor java_home =/usr/lib/jvm/java-8-openjdk-amd64
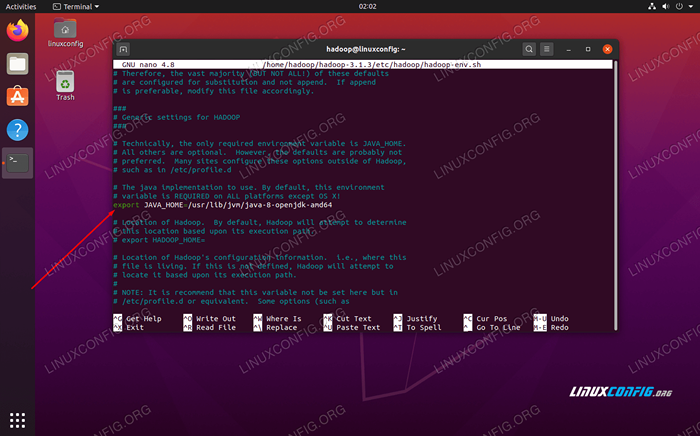 Ubah variabel lingkungan java_home
Ubah variabel lingkungan java_home Itu akan menjadi satu -satunya perubahan yang perlu kita lakukan di sini. Anda dapat menyimpan perubahan pada file dan menutupnya.
Perubahan konfigurasi di situs inti.file xml
Perubahan berikutnya yang perlu kita lakukan adalah di dalam situs inti.xml mengajukan. Buka dengan perintah ini:
$ nano ~/hadoop-3.1.3/etc/hadoop/core-site.xml
Masukkan konfigurasi berikut, yang menginstruksikan HDF untuk berjalan di LocalHost Port 9000 dan mengatur direktori untuk data sementara.
FS.defaultfs hdfs: // localhost: 9000 hadoop.TMP.dir/home/hadoop/hadooptmpdata 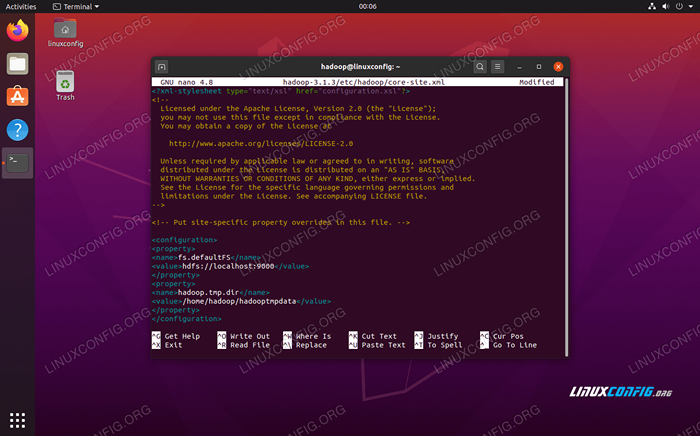 situs inti.Perubahan File Konfigurasi XML
situs inti.Perubahan File Konfigurasi XML Simpan perubahan Anda dan tutup file ini. Kemudian, buat direktori di mana data sementara akan disimpan:
$ mkdir ~/hadooptmpdata
Perubahan Konfigurasi di HDFS-Site.file xml
Buat dua direktori baru untuk Hadoop untuk menyimpan informasi namenode dan data.
$ mkdir -p ~/hdfs/namenode ~/hdfs/datasode
Kemudian, edit file berikut untuk memberi tahu Hadoop di mana menemukan direktori itu:
$ nano ~/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
Membuat perubahan berikut pada HDFS-SITE.xml file, sebelum menyimpan dan menutupnya:
dfs.Replikasi 1 DFS.nama.File dir: /// home/hadoop/hdfs/namenode dfs.data.File dir: /// home/hadoop/hdfs/datasode 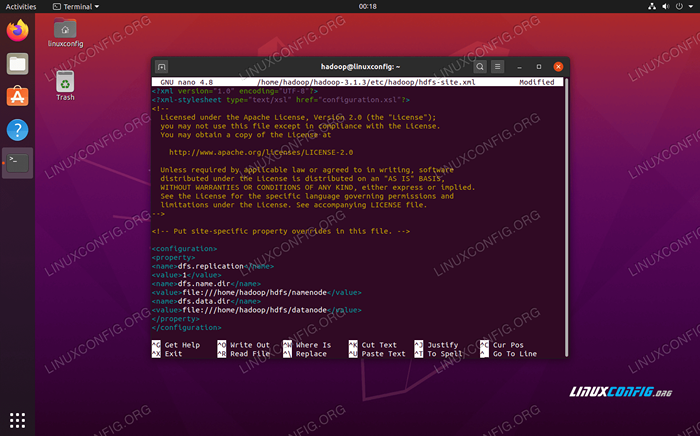 HDFS-SITE.Perubahan File Konfigurasi XML
HDFS-SITE.Perubahan File Konfigurasi XML Perubahan konfigurasi di situs mapred.file xml
Buka file konfigurasi MapReduce XML dengan perintah berikut:
$ nano ~/hadoop-3.1.3/etc/hadoop/mapred-site.xml
Dan membuat perubahan berikut sebelum menyimpan dan menutup file:
Mapreduce.kerangka.Nama benang 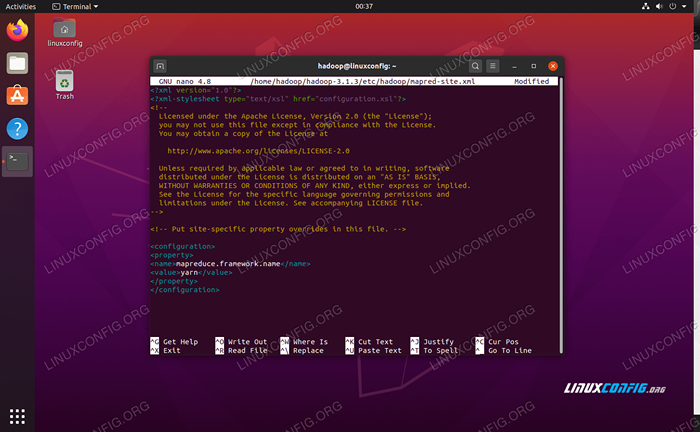 Situs Mapred.Perubahan File Konfigurasi XML
Situs Mapred.Perubahan File Konfigurasi XML Perubahan konfigurasi di situs benang.file xml
Buka file konfigurasi benang dengan perintah berikut:
$ nano ~/hadoop-3.1.3/etc/hadoop/situs benang.xml
Tambahkan entri berikut dalam file ini, sebelum menyimpan perubahan dan menutupnya:
Mapreduceyarn.NodeManager.aux-services mapreduce_shuffle 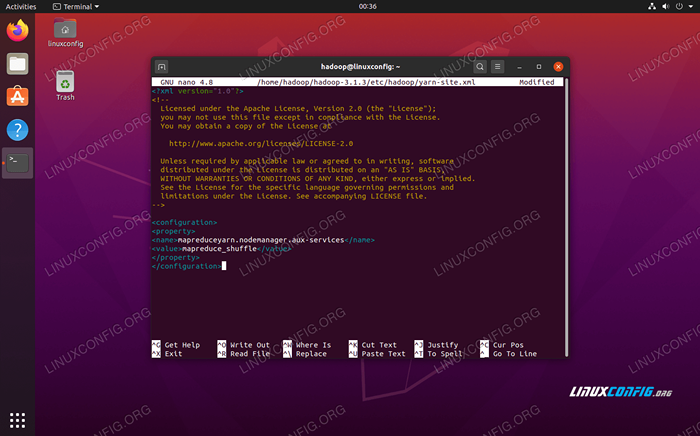 Perubahan file konfigurasi situs benang
Perubahan file konfigurasi situs benang Memulai klaster Hadoop
Sebelum menggunakan cluster untuk pertama kalinya, kita perlu memformat namenode. Anda dapat melakukannya dengan perintah berikut:
$ hdfs namenode -format
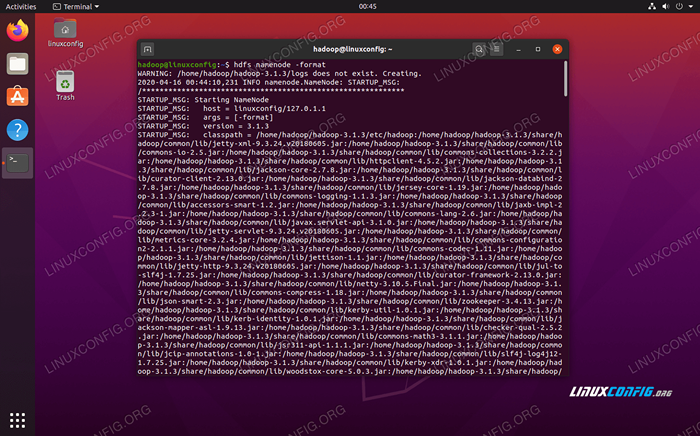 Memformat namenode HDFS
Memformat namenode HDFS Terminal Anda akan memuntahkan banyak informasi. Selama Anda tidak melihat pesan kesalahan apa pun, Anda dapat menganggap itu berhasil.
Selanjutnya, mulailah HDFS dengan menggunakan start-dfs.SH naskah:
$ start-dfs.SH
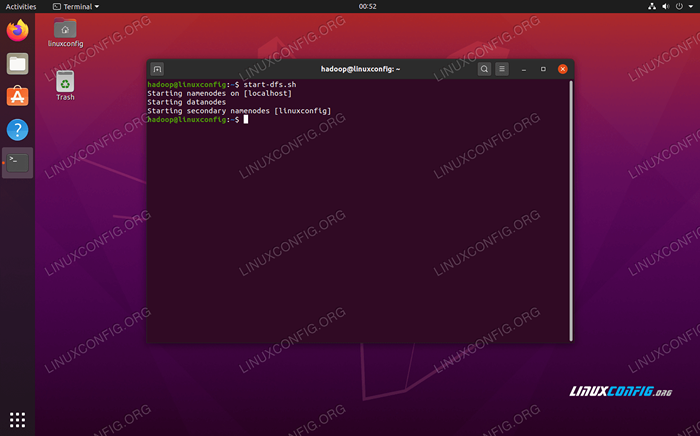 Jalankan Start-DFS.Skrip SH
Jalankan Start-DFS.Skrip SH Sekarang, mulailah layanan benang melalui Mulai-Bukur.SH naskah:
$ start-yarn.SH
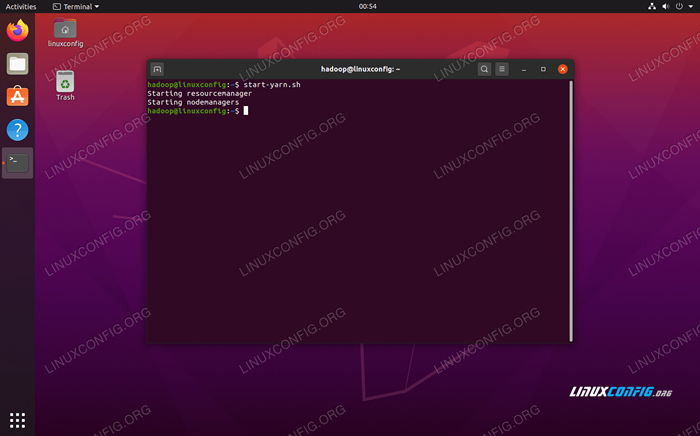 Jalankan Mulai-Besar.Skrip SH
Jalankan Mulai-Besar.Skrip SH Untuk memverifikasi semua layanan/daemon Hadoop dimulai dengan sukses, Anda dapat menggunakan JPS memerintah. Ini akan menunjukkan semua proses yang saat ini menggunakan java yang berjalan di sistem Anda.
$ jps
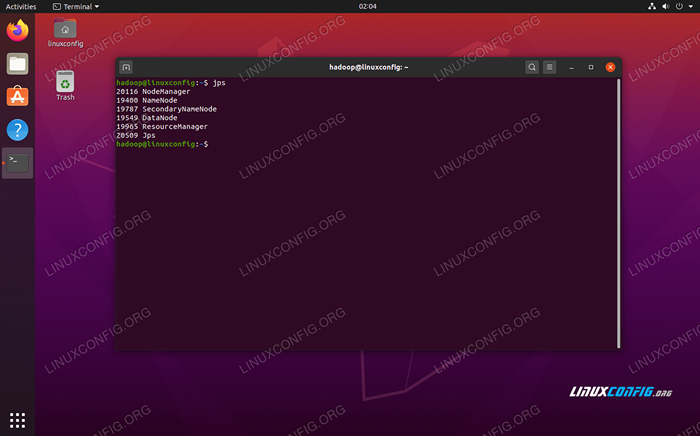 Jalankan JP untuk melihat semua proses yang bergantung pada Java dan memverifikasi komponen Hadoop sedang berjalan
Jalankan JP untuk melihat semua proses yang bergantung pada Java dan memverifikasi komponen Hadoop sedang berjalan Sekarang kita dapat memeriksa versi Hadoop saat ini dengan salah satu dari perintah berikut:
$ Hadoop Versi
atau
Versi $ HDFS
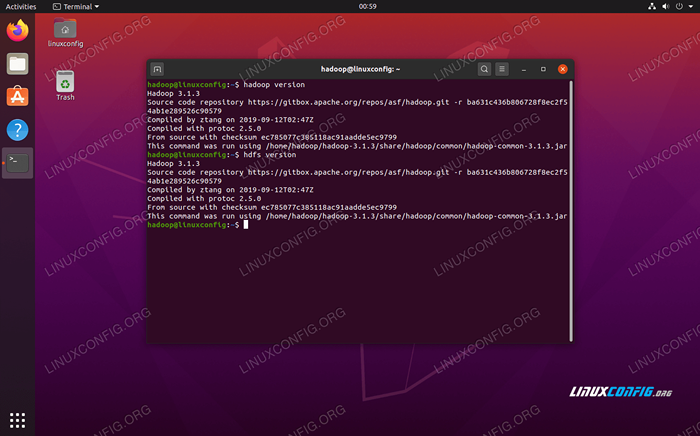 Memverifikasi instalasi Hadoop dan versi saat ini
Memverifikasi instalasi Hadoop dan versi saat ini Antarmuka baris perintah HDFS
Baris perintah HDFS digunakan untuk mengakses HDF dan membuat direktori atau mengeluarkan perintah lain untuk memanipulasi file dan direktori. Gunakan sintaks perintah berikut untuk membuat beberapa direktori dan daftar:
$ HDFS DFS -MKDIR /TEST $ HDFS DFS -MKDIR /HADOOPONUBUNTU $ HDFS DFS -LS /
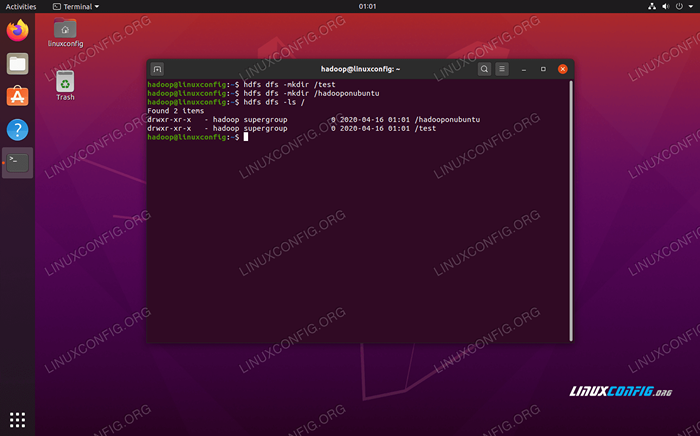 Berinteraksi dengan baris perintah HDFS
Berinteraksi dengan baris perintah HDFS Akses namenode dan benang dari browser
Anda dapat mengakses Web UI untuk Namenode dan Yarn Resource Manager melalui browser pilihan Anda, seperti Mozilla Firefox atau Google Chrome.
Untuk UI Web Namenode, navigasikan ke http: // hadoop-hostname-or-ip: 50070
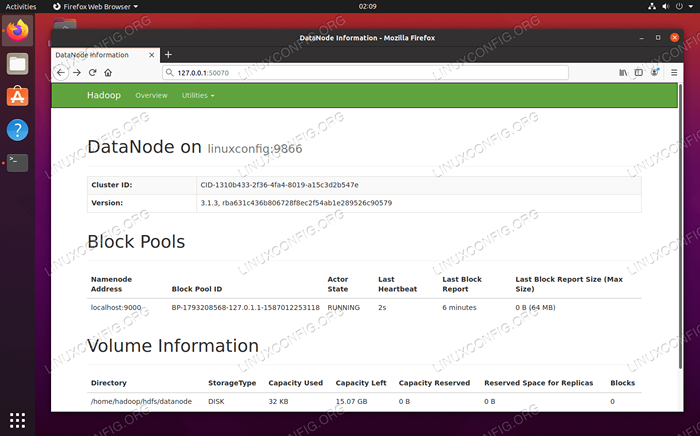 Antarmuka web datasode untuk Hadoop
Antarmuka web datasode untuk Hadoop Untuk mengakses antarmuka web manajer sumber daya benang, yang akan menampilkan semua pekerjaan yang sedang berjalan di kluster hadoop, navigasikan ke http: // hadoop-hostname-or-ip: 8088
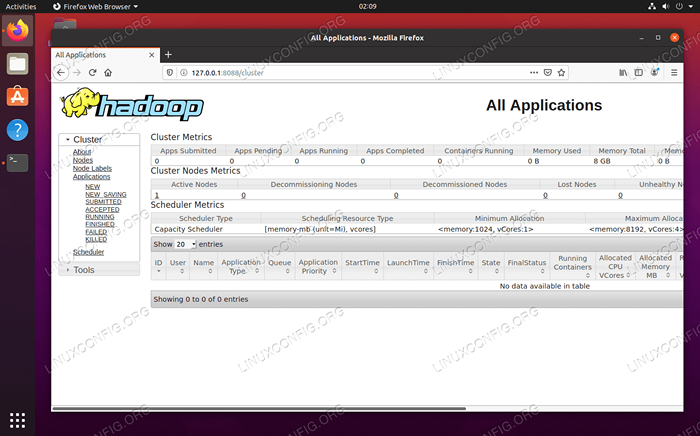 Antarmuka Web Manajer Sumber Daya Yarn untuk Hadoop
Antarmuka Web Manajer Sumber Daya Yarn untuk Hadoop Kesimpulan
Di artikel ini, kami melihat cara menginstal Hadoop pada satu node cluster di Ubuntu 20.04 FOSSA FOCAL. Hadoop memberi kami solusi yang bergantung pada berurusan dengan data besar, memungkinkan kami untuk memanfaatkan kelompok untuk penyimpanan dan pemrosesan data kami. Itu membuat hidup kita lebih mudah saat bekerja dengan set data besar dengan konfigurasi yang fleksibel dan antarmuka web yang nyaman.
Tutorial Linux Terkait:
- Hal -hal yang harus diinstal pada ubuntu 20.04
- Cara membuat cluster kubernetes
- Ubuntu 20.04 WordPress dengan Instalasi Apache
- Cara menginstal kubernet di ubuntu 20.04 FOSSA FOSSA Linux
- Bagaimana bekerja dengan WooCommerce Rest API dengan Python
- Loop bersarang dalam skrip bash
- Hal -hal yang harus dilakukan setelah menginstal ubuntu 20.04 FOSSA FOSSA Linux
- Menguasai loop skrip bash
- Cara menginstal kubernet di ubuntu 22.04 Jammy Jellyfish…
- Pengantar Otomatisasi Linux, Alat dan Teknik