

Menghapus baris duplikat dari file teks menggunakan baris perintah Linux
- 2538
- 56
- Darryl Ritchie
Menghapus baris duplikat dari file teks dapat dilakukan dari baris perintah Linux. Tugas seperti itu mungkin lebih umum dan perlu dari yang Anda pikirkan. Skenario paling umum di mana ini dapat membantu adalah dengan file log. Seringkali file log akan mengulangi informasi yang sama berulang -ulang, yang membuat file hampir mustahil untuk disaring, kadang -kadang membuat log tidak berguna.
Dalam panduan ini, kami akan menampilkan berbagai contoh baris perintah yang dapat Anda gunakan untuk menghapus baris duplikat dari file teks. Cobalah beberapa perintah di sistem Anda sendiri, dan gunakan mana pun yang paling nyaman untuk skenario Anda.
Dalam tutorial ini Anda akan belajar:
- Cara menghapus baris duplikat dari file saat menyortir
- Cara menghitung jumlah baris duplikat dalam file
- Cara menghapus garis duplikat tanpa mengurutkan file
Berbagai contoh untuk menghapus baris duplikat dari file teks di Linux | Kategori | Persyaratan, konvensi atau versi perangkat lunak yang digunakan |
|---|---|
| Sistem | Distro Linux apa pun |
| Perangkat lunak | BASH SHell |
| Lainnya | Akses istimewa ke sistem Linux Anda sebagai root atau melalui sudo memerintah. |
| Konvensi | # - mensyaratkan perintah linux yang diberikan untuk dieksekusi dengan hak istimewa root baik secara langsung sebagai pengguna root atau dengan menggunakan sudo memerintah$ - mensyaratkan perintah Linux yang diberikan untuk dieksekusi sebagai pengguna biasa |
Hapus baris duplikat dari file teks
Contoh -contoh ini akan bekerja pada distribusi linux apa pun, asalkan Anda menggunakan shell bash.
Untuk skenario contoh kami, kami akan bekerja dengan file berikut, yang hanya berisi nama -nama berbagai distribusi Linux. Ini adalah file teks yang sangat sederhana demi contoh, tetapi pada kenyataannya Anda dapat menggunakan metode ini pada dokumen yang mengandung ribuan baris berulang. Kita akan melihat cara menghapus semua duplikat dari file ini menggunakan contoh di bawah ini.
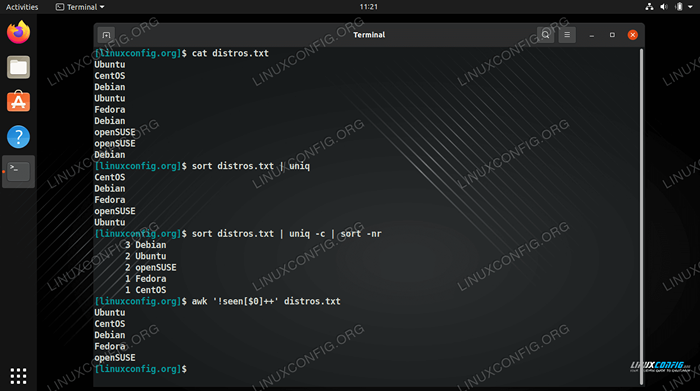
$ Distro Cat.txt ubuntu centos debian ubuntu fedora debian opensuse opensuse debian
- Itu
uniqPerintah dapat mengisolasi semua baris unik dari file kami, tetapi ini hanya berfungsi jika garis duplikat berdekatan satu sama lain. Agar garis berdekatan, mereka pertama -tama perlu diurutkan menjadi urutan abjad. Perintah berikut akan berfungsi dengan menggunakanmenyortirDanuniq.$ sortir distro.txt | uniq centos debian fedora opensuse ubuntu
Untuk membuat segalanya lebih mudah, kita bisa menggunakan
-udengan jenis untuk mendapatkan hasil yang sama persis, alih -alih menyalurkan ke uniq.
$ sort -u distro.txt centos debian fedora opensuse ubuntu
- Untuk melihat berapa banyak kejadian dari setiap baris dalam file, kita dapat menggunakan
-COpsi (hitung) dengan uniq.$ sortir distro.txt | uniq -c 1 centos 3 debian 1 fedora 2 opensuse 2 ubuntu
- Untuk melihat garis yang paling sering diulang, kita dapat menyalurkan perintah sortir lain dengan
-N(jenis numerik) dan-Ropsi terbalik. Ini memungkinkan kita untuk dengan cepat melihat baris mana yang paling digandakan dalam file - opsi praktis lain untuk menyaring log.$ sortir distro.txt | uniq -c | sort -nr 3 debian 2 ubuntu 2 opensuse 1 fedora 1 centos
- Satu masalah dengan menggunakan perintah sebelumnya adalah bahwa kita mengandalkan
menyortir. Ini berarti bahwa output akhir kami diurutkan secara abjad, atau diurutkan berdasarkan jumlah pengulangan seperti pada contoh sebelumnya. Terkadang ini mungkin merupakan hal yang baik, tetapi bagaimana jika kita membutuhkan file teks untuk mempertahankan pesanan sebelumnya? Kita dapat menghilangkan baris duplikat tanpa mengurutkan file dengan menggunakanAWKPerintah dalam sintaks berikut.$ awk '!terlihat [$ 0] ++ 'distro.txt ubuntu centos debian fedora opensuse
Dengan perintah ini, kejadian pertama dari suatu garis disimpan, dan garis duplikat di masa depan dibatalkan dari output.
- Contoh sebelumnya akan mengirim output langsung ke terminal Anda. Jika Anda menginginkan file teks baru dengan baris duplikat Anda difilter, Anda dapat mengadaptasi salah satu contoh ini dengan hanya menggunakan
>Operator bash seperti dalam perintah berikut.$ awk '!terlihat [$ 0] ++ 'distro.txt> distro-baru.txt
Ini harus menjadi semua perintah yang Anda butuhkan untuk menjatuhkan baris duplikat dari file, sementara secara opsional menyortir atau menghitung baris. Lebih banyak metode memang ada, tetapi ini adalah yang paling mudah digunakan dan diingat.
Menutup pikiran
Dalam panduan ini, kami melihat berbagai contoh perintah untuk menghapus baris duplikat dari file teks di Linux. Anda dapat menerapkan perintah ini untuk mencatat file atau jenis file plaintext lainnya yang memiliki baris duplikat. Kami juga belajar cara mengurutkan baris file teks atau menghitung jumlah duplikat, karena itu kadang -kadang dapat mempercepat mengisolasi informasi yang kami butuhkan dari dokumen.
Tutorial Linux Terkait:
- Hal -hal yang harus diinstal pada ubuntu 20.04
- Cara meningkatkan rendering font firefox di linux
- Pengantar Otomatisasi Linux, Alat dan Teknik
- Menguasai loop skrip bash
- Hal -hal yang harus dilakukan setelah menginstal ubuntu 20.04 FOSSA FOSSA Linux
- Perintah Linux: 20 perintah terpenting teratas yang Anda butuhkan untuk…
- Perintah Linux Dasar
- Cara memasang gambar iso di linux
- File Konfigurasi Linux: 30 Teratas Paling Penting
- Contoh RSYNC di Linux
- « Contoh Jaringan Dasar tentang Cara Menghubungkan Kontainer Docker
- Cara Mengkonfigurasi NFS di Linux »