

Perkenalan
- 2072
- 47
- Hector Kuhic
Dalam tutorial Gnu r cepat ini untuk model dan grafik statistik, kami akan memberikan contoh regresi linier sederhana dan belajar bagaimana melakukan analisis data statistik dasar seperti itu. Analisis ini akan disertai dengan contoh grafis, yang akan membawa kita lebih dekat untuk memproduksi plot dan bagan dengan gnu r. Jika Anda tidak terbiasa menggunakan R sama sekali, silakan lihat tutorial prasyarat: Tutorial GNU cepat untuk operasi dasar, fungsi dan struktur data.
Model dan formula di r
Kami mengerti a model dalam statistik sebagai deskripsi data yang ringkas. Presentasi data seperti itu biasanya dipamerkan dengan a Formula Matematika. R memiliki cara sendiri untuk mewakili hubungan antar variabel. Misalnya, hubungan berikut y = c0+C1X1+C2X2+... +cNXN+r dalam r tertulis sebagai
y ~ x1+x2+...+xn,
yang merupakan objek formula.
Contoh regresi linier
Mari kita sekarang memberikan contoh regresi linier untuk Gnu R, yang terdiri dari dua bagian. Pada bagian pertama dari contoh ini kita akan mempelajari hubungan antara pengembalian indeks keuangan yang didenominasi dalam dolar AS dan pengembalian tersebut dalam dolar Kanada. Selain itu pada bagian kedua dari contoh kami menambahkan satu variabel lagi ke analisis kami, yang merupakan pengembalian indeks yang dalam oro.
Regresi linier sederhana
Unduh contoh file data ke direktori kerja Anda: regresi-example-gnu-r.CSV
Mari kita jalankan R di Linux dari lokasi direktori kerja hanya dengan
$ R
dan membaca data dari contoh file data kami:
> kembali<-read.csv("regression-example-gnu-r.csv",header=TRUE) Anda dapat melihat nama -nama variabel mengetik
> Nama (kembali)
[1] "USA" "Kanada" "Jerman"
Saatnya mendefinisikan model statistik kami dan menjalankan regresi linier. Ini dapat dilakukan dalam beberapa baris kode berikut:
> y<-returns[,1]
> x1<-returns[,2]
> kembali.LM<-lm(formula=y~x1)
Untuk menampilkan ringkasan analisis regresi, kami menjalankan ringkasan() Fungsi pada objek yang dikembalikan kembali.LM. Itu adalah,
> ringkasan (kembali.LM)
Panggilan:
lm (rumus = y ~ x1)
Residu:
Min 1q median 3q max
-0.038044 -0.001622 0.000001 0.001631 0.050251
Koefisien:
Perkirakan Std. Kesalahan t nilai pr (> | t |)
(Mencegat) 3.174E-05 3.862E-05 0.822 0.411
x1 9.275E-01 4.880e-03 190.062 <2e-16 ***
---
Menandakan. Kode: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.'0.1 "1
Kesalahan standar residual: 0.003921 pada 10332 derajat kebebasan
Beberapa r-squared: 0.7776, R-squared yang disesuaikan: 0.7776
F-statistik: 3.612e+04 pada 1 dan 10332 df, p-value: < 2.2e-16
Fungsi ini menghasilkan hasil yang sesuai di atas. Koefisien yang diperkirakan ada di sini C0~ 3.174e-05 dan c1 ~ 9.275E-01. Nilai-p di atas menunjukkan bahwa estimasi intersep c0 tidak berbeda secara signifikan dari nol, oleh karena itu dapat diabaikan. Koefisien kedua secara signifikan berbeda dari nol karena nilai-p<2e-16. Therefore, our estimated model is represented by: y=0.93 x1. Apalagi R-Squared adalah 0.78, artinya sekitar 78% dari varians dalam variabel y dijelaskan oleh model.
Beberapa regresi linier
Sekarang mari kita tambahkan satu variabel lagi ke dalam model kami dan lakukan analisis regresi berganda. Pertanyaannya sekarang adalah apakah menambahkan satu variabel lagi ke model kami menghasilkan model yang lebih andal.
> x2<-returns[,3]
> kembali.LM<-lm(formula=y~x1+x2)
> ringkasan (kembali.LM)
Panggilan:
LM (rumus = y ~ x1 + x2)
Residu:
Min 1q median 3q max
-0.0244426 -0.0016599 0.0000053 0.0016889 0.0259443
Koefisien:
Perkirakan Std. Kesalahan t nilai pr (> | t |)
(Mencegat) 2.385E-05 3.035E-05 0.786 0.432
x1 6.736E-01 4.978E-03 135.307 <2e-16 ***
x2 3.026E-01 3.783E-03 80.001 <2e-16 ***
---
Menandakan. Kode: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.'0.1 "1
Kesalahan standar residual: 0.003081 pada 10331 derajat kebebasan
Beberapa r-squared: 0.8627, R-squared yang disesuaikan: 0.8626
F-statistik: 3.245e+04 pada 2 dan 10331 df, p-value: < 2.2e-16
Di atas, kita dapat melihat hasil analisis regresi berganda setelah menambahkan variabel x2. Variabel ini mewakili pengembalian indeks keuangan dalam euro. Kami sekarang mendapatkan model yang lebih andal, karena R-squared yang disesuaikan adalah 0.86, yang lebih besar dari nilai yang diperoleh sebelum sama dengan 0.76. Perhatikan, bahwa kami membandingkan R-squared yang disesuaikan karena itu mengambil jumlah nilai dan ukuran sampel diperhitungkan. Sekali lagi koefisien intersep tidak signifikan, oleh karena itu, model yang diperkirakan dapat direpresentasikan sebagai: y = 0.67x1+0.30x2.
Perhatikan juga bahwa kami dapat merujuk pada vektor data kami dengan nama mereka, misalnya
> LM (mengembalikan $ USA ~ pengembalian $ Kanada)
Panggilan:
LM (Formula = Pengembalian $ USA ~ Pengembalian $ Kanada)
Koefisien:
(Mencegat) mengembalikan $ Kanada
3.174E-05 9.275E-01
Grafik
Di bagian ini kami akan menunjukkan cara menggunakan R untuk visualisasi beberapa properti dalam data. Kami akan mengilustrasikan angka yang diperoleh dengan fungsi seperti itu merencanakan(), boxplot (), hist (), qqnorm ().
Sebaran plot
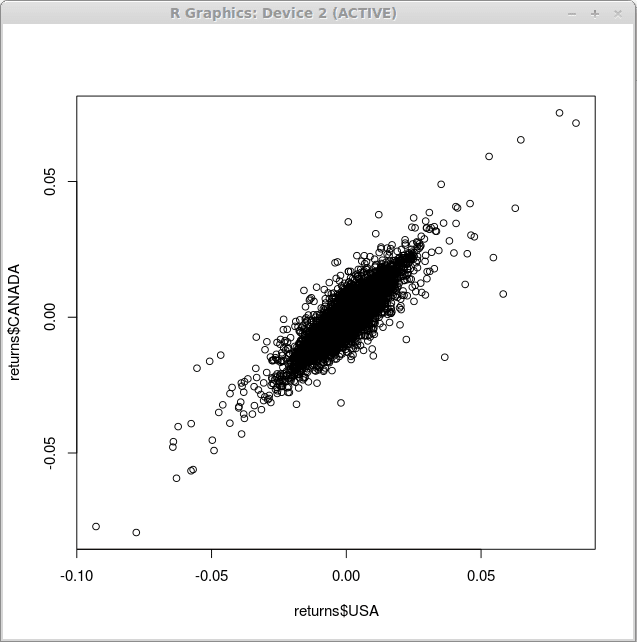
Mungkin yang paling sederhana dari semua grafik yang dapat Anda peroleh dengan R adalah plot sebar. Untuk mengilustrasikan hubungan antara denominasi dolar AS dari pengembalian indeks keuangan dan denominasi dolar Kanada kami menggunakan fungsi tersebut merencanakan() sebagai berikut:
> Plot (mengembalikan $ USA, mengembalikan $ Kanada)
Sebagai hasil dari pelaksanaan fungsi ini, kami memperoleh diagram pencar seperti yang dipamerkan di bawah ini
Salah satu argumen terpenting yang dapat Anda lewati ke fungsi tersebut merencanakan() adalah 'tipe'. Itu menentukan jenis plot apa yang harus ditarik. Jenis yang mungkin adalah:
• '"P“'Untuk *p *oints
• '"l“'Untuk *l *ines
• '"B"' untuk berdua
• '"C"'Untuk garis bagian saja dari'" b "'
• '"Hai“'Untuk keduanya'*o*displotted '
• '"H“'Untuk'*h*iStogram 'seperti (atau' kepadatan tinggi ') garis vertikal
• '"S“'Untuk tangga *s *Teps
• '"S“'Untuk tipe *s *teps lainnya
• '"N“'Untuk tidak merencanakan
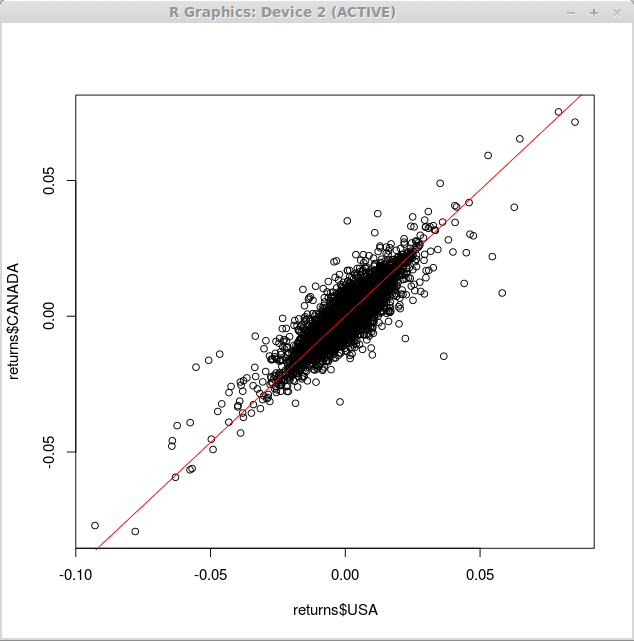
Untuk overlay garis regresi di atas diagram sebar di atas kami menggunakan melengkung() berfungsi dengan argumen 'Tambahkan' dan 'col', yang menentukan bahwa garis harus ditambahkan ke plot yang ada dan warna garis yang diplot, masing -masing.
> kurva (0.93*x, -0.1,0.1, add = true, col = 2)
Akibatnya, kami memperoleh perubahan berikut dalam grafik kami:
Untuk informasi lebih lanjut tentang fungsi plot () atau lines () fungsi membantu(), contohnya
> Bantuan (plot)
Plot kotak
Mari kita lihat bagaimana cara menggunakan boxplot () Fungsi untuk mengilustrasikan statistik deskriptif data. Pertama, menghasilkan ringkasan statistik deskriptif untuk data kami oleh ringkasan() fungsi dan kemudian menjalankan boxplot () Fungsi untuk pengembalian kami:
> ringkasan (kembali)
USA Canada Jerman
Min. : -0.0928805 mnt. : -0.0792810 mnt. : -0.0901134
Qust q.: -0.0036463 1 qu.: -0.0038282 1st Qu.: -0.0046976
Median: 0.0005977 Median: 0.0005318 Median: 0.0005021
Berarti: 0.0003897 berarti: 0.0003859 berarti: 0.0003499
Qu ke -3.: 0.0046566 3 qu.: 0.0047591 qu 3.: 0.0056872
Max. : 0.0852364 MAX. : 0.0752731 MAX. : 0.0927688
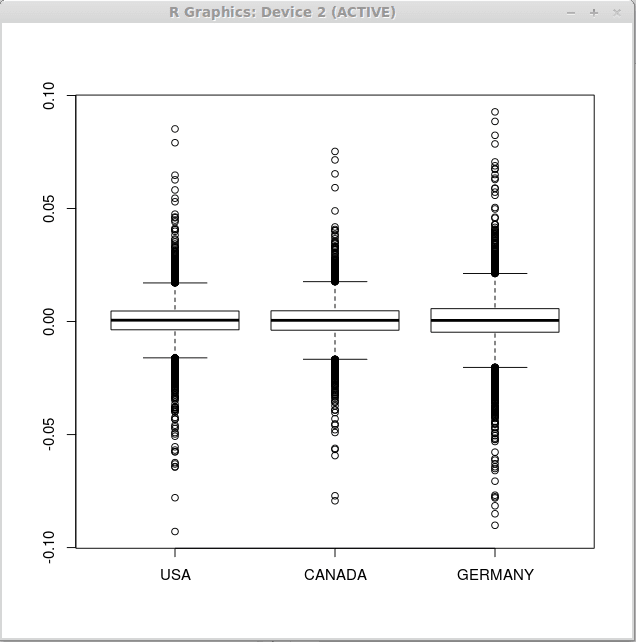
Perhatikan bahwa statistik deskriptif serupa untuk ketiga vektor, oleh karena itu kita dapat mengharapkan boxplot yang serupa untuk semua set pengembalian keuangan. Sekarang, jalankan fungsi boxplot () sebagai berikut
> boxplot (kembali)
Akibatnya kami memperoleh tiga plot kotak berikut.
Histogram
Di bagian ini kita akan melihat histogram. Histogram frekuensi sudah diperkenalkan dalam pengantar sistem operasi Linux. Kami sekarang akan menghasilkan histogram kerapatan untuk pengembalian yang dinormalisasi dan membandingkannya dengan kurva kerapatan normal.
Mari kita, pertama, normalkan pengembalian indeks yang didenominasi dalam dolar AS untuk mendapatkan rata -rata nol dan varian yang sama dengan satu agar dapat membandingkan data nyata dengan fungsi kerapatan normal standar teoritis.
> retus.norma<-(returns$USA-mean(returns$USA))/sqrt(var(returns$USA))
> rata -rata (retus.norma)
[1] -1.053152E-17
> var (retus.norma)
[1] 1
Sekarang, kami menghasilkan histogram kerapatan untuk pengembalian yang dinormalisasi dan plot kurva kepadatan normal standar di atas histogram tersebut. Ini dapat dicapai dengan ekspresi R berikut
> hist (retus.norma, istirahat = 50, freq = false)
> kurva (dnorm (x),-10,10, add = true, col = 2)
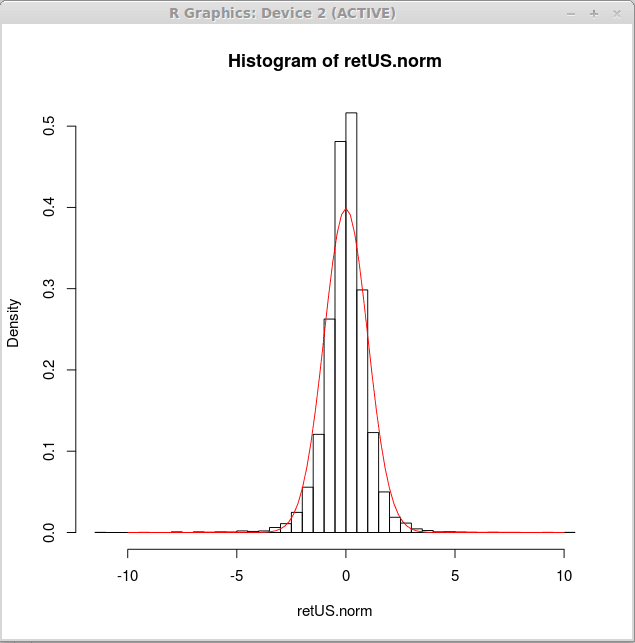
Secara visual, kurva normal tidak sesuai dengan data dengan baik. Distribusi yang berbeda mungkin lebih cocok untuk pengembalian keuangan. Kami akan belajar cara menyesuaikan distribusi ke data dalam artikel selanjutnya. Saat ini kita dapat menyimpulkan bahwa distribusi yang lebih cocok akan lebih dipetik di tengah dan akan memiliki ekor yang lebih berat.
Qq-plot
Grafik lain yang berguna dalam analisis statistik adalah qq-plot. Plot QQ adalah plot kuantil kuantil, yang membandingkan kuantil dari kepadatan empiris dengan kuantil dari kepadatan teoretis. Jika ini cocok dengan baik kita akan melihat garis lurus. Sekarang mari kita bandingkan distribusi residu yang diperoleh dengan analisis regresi kami di atas. Pertama, kami akan mendapatkan plot QQ untuk regresi linier sederhana dan kemudian untuk beberapa regresi linier. Jenis plot QQ yang akan kami gunakan adalah qq-plot normal, yang berarti bahwa kuantil teoretis dalam grafik sesuai dengan kuantil dari distribusi normal.
Plot pertama yang sesuai dengan residu regresi linier sederhana diperoleh dengan fungsi tersebut qqnorm () dengan cara berikut:
> kembali.LM<-lm(returns$US~returns$CANADA)
> qqnorm (kembali.residu lm $)
Grafik yang sesuai ditampilkan di bawah ini:
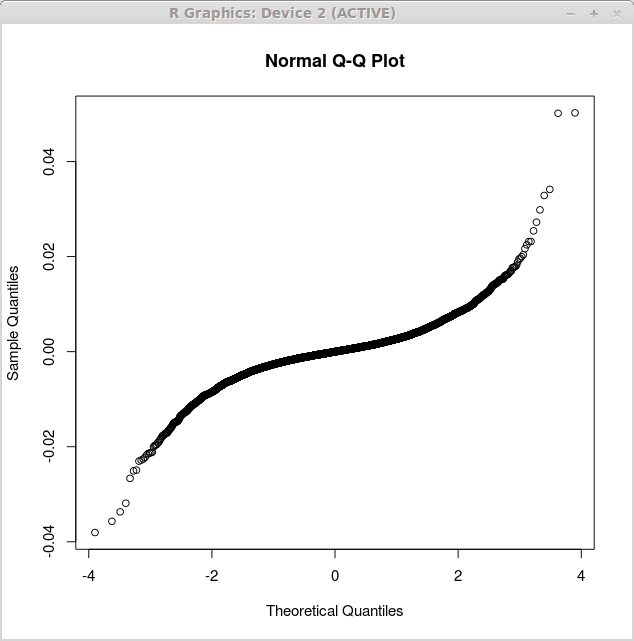
Plot kedua sesuai dengan residu regresi linier berganda dan diperoleh sebagai:
> kembali.LM<-lm(returns$US~returns$CANADA+returns$GERMANY)
> qqnorm (kembali.residu lm $)
Plot ini ditampilkan di bawah ini:
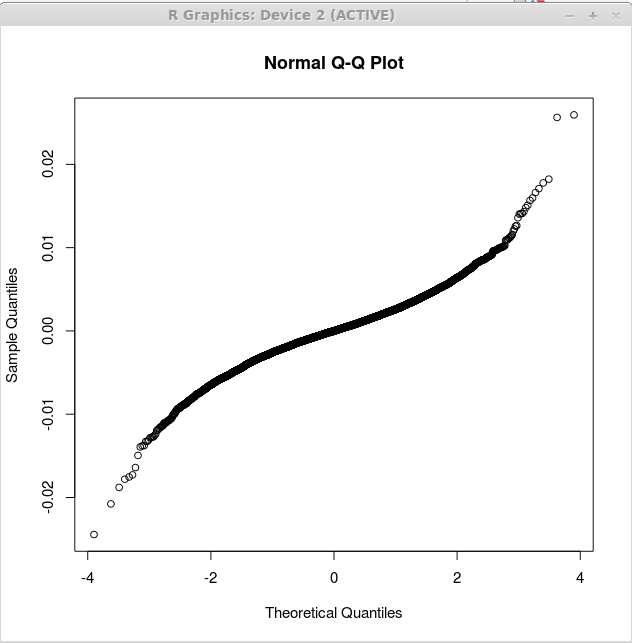
Perhatikan bahwa plot kedua lebih dekat ke garis lurus. Ini menunjukkan bahwa residu yang diproduksi oleh analisis regresi berganda lebih dekat dengan yang didistribusikan secara normal. Ini mendukung lebih lanjut model kedua sebagai lebih berguna selama model regresi pertama.
Kesimpulan
Dalam artikel ini kami telah memperkenalkan pemodelan statistik dengan Gnu r pada contoh regresi linier. Kami juga telah membahas beberapa yang sering digunakan dalam grafik statistik. Saya harap ini telah membuka pintu untuk analisis statistik dengan gnu r untuk Anda. Kami akan, dalam artikel selanjutnya, membahas aplikasi R yang lebih kompleks untuk pemodelan statistik serta pemrograman jadi teruslah membaca.
Seri Tutorial Gnu:
Bagian I: Tutorial Pengantar Gnu R:
- Pengantar Gnu R pada Sistem Operasi Linux
- Menjalankan Gnu R pada Sistem Operasi Linux
- Tutorial Gnu R cepat untuk operasi dasar, fungsi dan struktur data
- Tutorial Gnu R cepat untuk model dan grafik statistik
- Cara Menginstal dan Menggunakan Paket di Gnu R
- Membangun Paket Dasar di Gnu R
Bagian II: Bahasa Gnu R:
- Tinjauan bahasa pemrograman Gnu
Tutorial Linux Terkait:
- Pengantar Otomatisasi Linux, Alat dan Teknik
- Hal -hal yang harus diinstal pada ubuntu 20.04
- Menguasai loop skrip bash
- Hal -hal yang harus dilakukan setelah menginstal ubuntu 20.04 FOSSA FOSSA Linux
- Loop bersarang dalam skrip bash
- Mint 20: Lebih baik dari Ubuntu dan Microsoft Windows?
- Menangani input pengguna dalam skrip bash
- Ubuntu 20.04 trik dan hal -hal yang mungkin tidak Anda ketahui
- Manipulasi data besar untuk kesenangan dan keuntungan bagian 1
- Ubuntu 20.04 Panduan