

Cara Mengatur Hadoop di Ubuntu 18.04 & 16.04 lts

- 2592
- 590
- Dominick Barton
Apache Hadoop 3.1 memiliki perbaikan yang nyata. Banyak perbaikan bug di atas stabil sebelumnya 3.0 rilis. Versi ini memiliki banyak peningkatan HDF dan MapReduce. Tutorial ini akan membantu Anda menginstal dan mengonfigurasi Hadoop 3.1.2 Cluster simpul tunggal di Ubuntu 18.04, 16.04 LTS dan Sistem Linuxmint. Artikel ini telah diuji dengan Ubuntu 18.04 lts.
Langkah 1 - Prerequsities
Java adalah persyaratan utama untuk menjalankan Hadoop pada sistem apa pun, jadi pastikan Anda telah menginstal Java pada sistem Anda menggunakan perintah berikut. Jika Anda tidak menginstal Java di sistem Anda, gunakan salah satu tautan berikut untuk menginstalnya terlebih dahulu.
- Instal Oracle Java 11 di Ubuntu 18.04 LTS (Bionic)
- Instal Oracle Java 11 di Ubuntu 16.04 LTS (xenial)
Langkah 2 - Buat Pengguna untuk HadDop
Kami merekomendasikan membuat akun normal (atau root) untuk Hadoop Working. Untuk membuat akun menggunakan perintah berikut.
Adduser Hadoop
Setelah membuat akun, itu juga diperlukan untuk mengatur SSH berbasis kunci ke akunnya sendiri. Untuk melakukan ini gunakan, jalankan perintah berikut.
su -hadoop ssh -keygen -t rsa -p "-f ~/.SSH/ID_RSA Cat ~/.ssh/id_rsa.pub >> ~//.ssh/otorisasi_keys chmod 0600 ~/.ssh/otorisasi_keys
Sekarang, ssh ke localhost dengan pengguna Hadoop. Ini seharusnya tidak meminta kata sandi tetapi pertama kali akan meminta untuk menambahkan RSA ke daftar host yang diketahui.
SSH Localhost Exit
Langkah 3 - Unduh Arsip Sumber Hadoop
Pada langkah ini, unduh Hadoop 3.1 file arsip sumber menggunakan perintah di bawah ini. Anda juga dapat memilih cermin unduhan alternatif untuk meningkatkan kecepatan unduhan.
CD ~ wget http: // www-eu.Apache.org/dist/hadoop/common/hadoop-3.1.2/Hadoop-3.1.2.ter.GZ TAR XZF HADOOP-3.1.2.ter.GZ MV Hadoop-3.1.2 Hadoop
Langkah 4 - Pengaturan Hadoop Pseudo -Distributed Mode
4.1. Setup variabel lingkungan hadoop
Mengatur variabel lingkungan yang digunakan oleh hadoop. Edit ~/.Bashrc file dan tambahkan nilai berikut di akhir file.
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$ HADOOP_HOME/SBIN: $ HADOOP_HOME/BIN
Kemudian, terapkan perubahan dalam lingkungan yang berjalan saat ini
Sumber ~/.Bashrc
Sekarang edit $ Hadoop_home/etc/hadoop/hadoop-env.SH file dan set Java_home Variabel Lingkungan. Ubah Java Path sesuai pemasangan di sistem Anda. Jalur ini dapat bervariasi sesuai dengan versi sistem operasi Anda dan sumber instalasi. Jadi pastikan Anda menggunakan jalur yang benar.
vim $ hadoop_home/etc/hadoop/hadoop-env.SH
Perbarui entri di bawah ini:
Ekspor java_home =/usr/lib/jvm/java-11-oracle
4.2. Mengatur file konfigurasi Hadoop
Hadoop memiliki banyak file konfigurasi, yang perlu dikonfigurasi sesuai persyaratan infrastruktur Hadoop Anda. Mari kita mulai dengan konfigurasi dengan pengaturan klaster node tunggal Hadoop dasar. Pertama, arahkan ke lokasi di bawah
cd $ hadoop_home/etc/hadoop
Edit situs inti.xml
FS.bawaan.Nama hdfs: // localhost: 9000
Edit HDFS-Site.xml
dfs.Replikasi 1 DFS.nama.File dir: /// home/hadoop/hadoopdata/hdfs/namenode dfs.data.File dir: /// home/hadoop/hadoopdata/hdfs/datanode
Edit-situs Mapred.xml
Mapreduce.kerangka.Nama benang
Edit situs benang.xml
benang.NodeManager.aux-services mapreduce_shuffle
4.3. Format namenode
Sekarang format namenode menggunakan perintah berikut, pastikan direktori penyimpanan itu
HDFS Namenode -Format
Output sampel:
PERINGATAN:/home/hadoop/hadoop/log tidak ada. Menciptakan. 2018-05-02 17: 52: 09.678 Info Namenode.Namenode: startup_msg: /********************************************* *************** startup_msg: Memulai namenode startup_msg: host = tecadmin/127.0.1.1 startup_msg: args = [-format] startup_msg: versi = 3.1.2… 2018-05-02 17: 52: 13.717 Info Umum.Penyimpanan: Direktori Penyimpanan/Rumah/Hadoop/HadoopData/HDFS/Namenode telah berhasil diformat. 2018-05-02 17: 52: 13.806 info namenode.FSIMAGEFORMATPROTOBUF: Menyimpan File Gambar/Rumah/Hadoop/HadoopData/HDFS/Namenode/Saat Ini/FSIMAGE.CKPT_0000000000000000000 Menggunakan No Compression 2018-05-02 17: 52: 14.161 Info Namenode.FSIMAGEFORMATPROTOBUF: File Gambar/Rumah/Hadoop/HadoopData/HDFS/Namenode/Saat Ini/FSIMAGE.CKPT_0000000000000000000 Ukuran 391 byte disimpan dalam 0 detik . 2018-05-02 17: 52: 14.224 info namenode.NnstorageretentionManager: akan mempertahankan 1 gambar dengan txid> = 0 2018-05-02 17: 52: 14.282 info namenode.Namenode: shutdown_msg: /********************************************* *******************_Msg: Mematikan namenode di Tecadmin/127.0.1.1 *********************************************** ***********/
Langkah 5 - Mulai Hadoop Cluster
Mari kita mulai kluster hadoop Anda menggunakan skrip yang disediakan oleh Hadoop. Navigasi saja ke direktori $ hadoop_home/sbin Anda dan jalankan skrip satu per satu.
CD $ HADOOP_HOME/SBIN/
Sekarang jalankan start-dfs.SH naskah.
./start-dfs.SH
Lalu jalankan Mulai-Bukur.SH naskah.
./mulai-yarn.SH
Langkah 6 - Akses Layanan Hadoop di Browser
Hadoop Namenode dimulai dengan port default 9870. Akses server Anda di port 9870 di browser web favorit Anda.
http: // svr1.tecadmin.net: 9870/
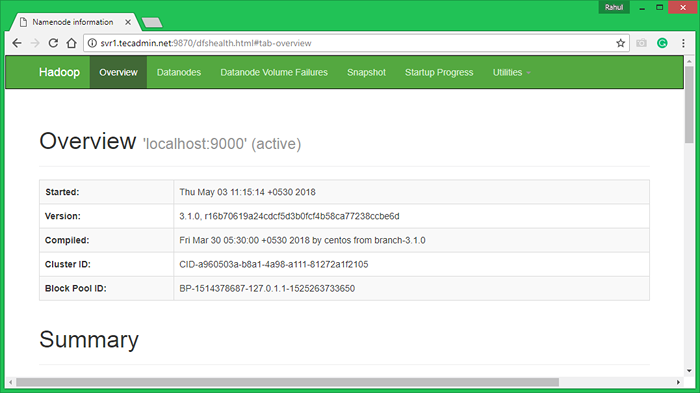
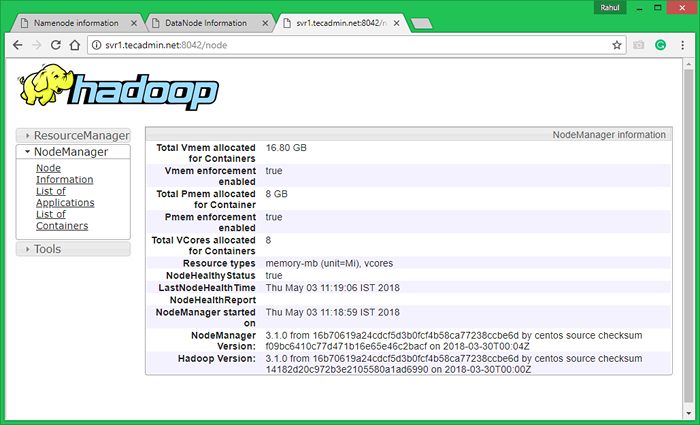
Sekarang akses port 8042 untuk mendapatkan informasi tentang cluster dan semua aplikasi
http: // svr1.tecadmin.net: 8042/
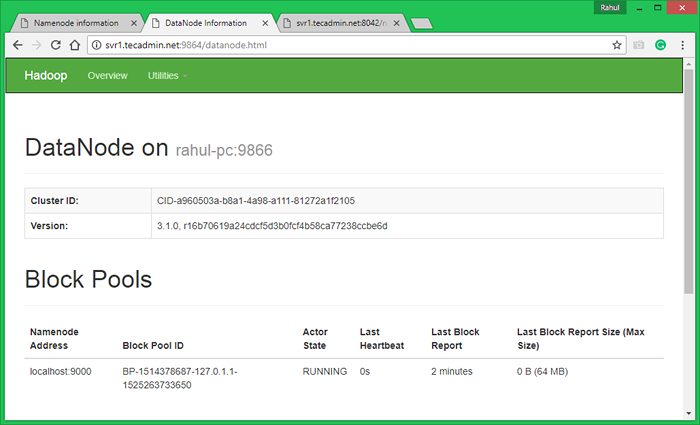
Akses port 9864 untuk mendapatkan detail tentang node hadoop Anda.
http: // svr1.tecadmin.net: 9864/
Langkah 7 - Test Hadoop Single Node Setup
7.1. Buat direktori HDFS diperlukan dengan menggunakan perintah berikut.
bin/hdfs DFS -MKDIR/BIN USER/HDFS DFS -MKDIR/USER/HADOOP
7.2. Salin semua file dari sistem file lokal/var/log/httpd ke sistem file terdistribusi hadoop menggunakan perintah di bawah ini
Bin/HDFS DFS -Put/Var/Log/Apache2 Log
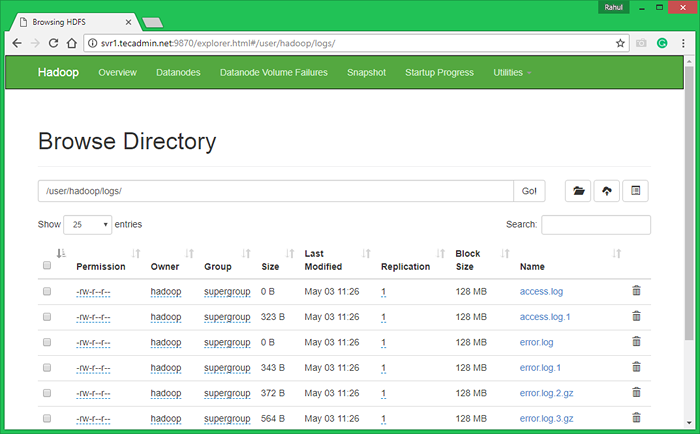
7.3. Jelajahi sistem file terdistribusi Hadoop dengan membuka di bawah URL di browser. Anda akan melihat folder Apache2 dalam daftar. Klik pada nama folder yang akan dibuka dan Anda akan menemukan semua file log di sana.
http: // svr1.tecadmin.net: 9870/explorer.html#/user/hadoop/log/
7.4 - Sekarang Salin Direktori Log untuk Sistem File Terdistribusi Hadoop ke Sistem File Lokal.
BIN/HDFS DFS -GET LOGS/TMP/LOG LS -L/TMP/LOG/
Anda juga dapat memeriksa tutorial ini untuk menjalankan contoh pekerjaan MapReduce WordCount menggunakan baris perintah.
- « Cara Mendeteksi Lingkungan Desktop di Baris Perintah Linux
- Cara mengunduh dan mengunggah file dengan perintah sftp »