

Cara Memulihkan Data dan Membangun Kembali Gagal Perangkat Lunak RAID's - Bagian 8

- 1533
- 56
- Dr. Travis Bahringer
Dalam artikel sebelumnya dari seri RAID ini, Anda beralih dari nol ke RAID HERO. Kami meninjau beberapa konfigurasi RAID perangkat lunak dan menjelaskan hal -hal penting dari masing -masing, bersama dengan alasan mengapa Anda akan condong ke arah satu atau yang lain tergantung pada skenario spesifik Anda.
 Recover Rebuild Gagal Perangkat Lunak RAID's - Bagian 8
Recover Rebuild Gagal Perangkat Lunak RAID's - Bagian 8 Dalam panduan ini kita akan membahas cara membangun kembali array serangan perangkat lunak tanpa kehilangan data saat terjadi kegagalan disk. Untuk singkatnya, kami hanya akan mempertimbangkan a RAID 1 Pengaturan - tetapi konsep dan perintah berlaku untuk semua kasus.
Skenario Pengujian Serangan
Sebelum melanjutkan lebih lanjut, pastikan Anda telah mengatur a RAID 1 Array Mengikuti instruksi yang disediakan di Bagian 3 dari seri ini: Cara Mengatur RAID 1 (Mirror) di Linux.
Satu -satunya variasi dalam kasus kami saat ini adalah:
1) Versi Centos (V7) yang berbeda dari yang digunakan dalam artikel itu (v6.5), dan
2) Ukuran disk yang berbeda untuk /dev/sdb Dan /dev/sdc (Masing -masing 8 GB).
Selain itu, jika Selinux diaktifkan dalam mode penegakan, Anda harus menambahkan label yang sesuai ke direktori tempat Anda akan memasang perangkat RAID. Jika tidak, Anda akan mengalami pesan peringatan ini saat mencoba untuk memasangnya:
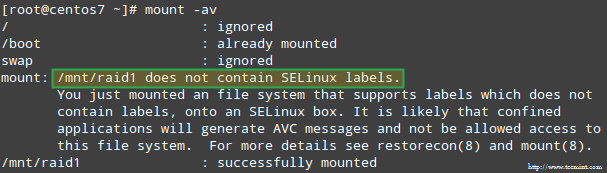 Selinux Raid Mount Error
Selinux Raid Mount Error Anda dapat memperbaikinya dengan menjalankan:
# restorecon -r /mnt /raid1
Menyiapkan pemantauan serangan
Ada berbagai alasan mengapa perangkat penyimpanan dapat gagal (SSD telah sangat mengurangi kemungkinan hal ini terjadi, tetapi terlepas dari penyebabnya Anda dapat yakin bahwa masalah dapat terjadi kapan saja dan Anda harus siap untuk mengganti yang gagal yang gagal bagian dan untuk memastikan ketersediaan dan integritas data Anda.
Kata nasihat terlebih dahulu. Bahkan saat Anda dapat memeriksa /proc/mdstat Untuk memeriksa status penggerebekan Anda, ada metode yang lebih baik dan hemat waktu yang terdiri dari berlari mdadm Dalam mode monitor + pemindaian, yang akan mengirim peringatan melalui email ke penerima yang telah ditentukan sebelumnya.
Untuk mengatur ini, tambahkan baris berikut /etc/mdadm.conf:
Mailaddr [email dilindungi]
Dalam hal ini:
Mailaddr [email dilindungi]
 Peringatan email pemantauan pemantauan
Peringatan email pemantauan pemantauan Untuk berlari mdadm Dalam mode monitor + pemindaian, tambahkan entri crontab berikut sebagai root:
@Reboot /sbin /mdadm --monitor -scan --oneshot
Secara default, mdadm akan memeriksa array serangan setiap 60 detik dan mengirim peringatan jika menemukan masalah. Anda dapat memodifikasi perilaku ini dengan menambahkan --menunda Opsi untuk entri crontab di atas bersama dengan jumlah detik (misalnya, --menunda 1800 berarti 30 menit).
Akhirnya, pastikan Anda memiliki Agen pengguna surat (MUA) diinstal, seperti Mutt atau Mailx. Jika tidak, Anda tidak akan menerima peringatan apa pun.
Dalam satu menit kita akan melihat peringatan apa yang dikirim mdadm seperti.
Mensimulasikan dan mengganti perangkat penyimpanan RAID yang gagal
Untuk mensimulasikan masalah dengan salah satu perangkat penyimpanan di array RAID, kami akan menggunakan --mengelola Dan --Set-Faulty Opsi sebagai berikut:
# mdadm --Manage --set-faulty /dev /md0 /dev /sdc1
Ini akan menghasilkan /dev/sdc1 ditandai sebagai salah, seperti yang bisa kita lihat /proc/mdstat:
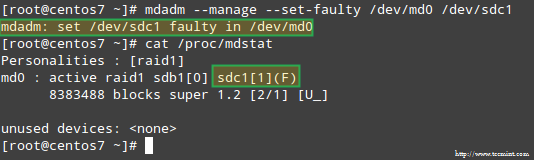 Merangsang masalah dengan penyimpanan serangan
Merangsang masalah dengan penyimpanan serangan Lebih penting lagi, mari kita lihat apakah kami menerima peringatan email dengan peringatan yang sama:
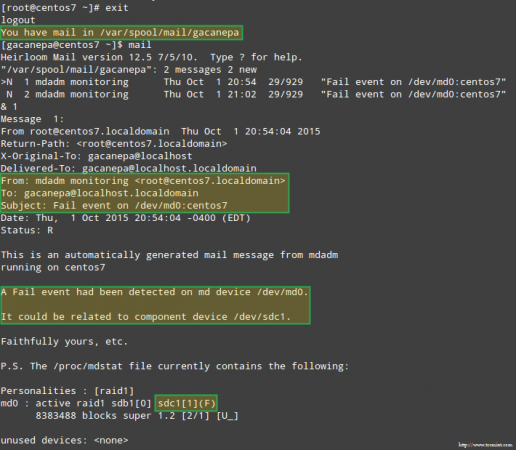 Peringatan email di perangkat RAID yang gagal
Peringatan email di perangkat RAID yang gagal Dalam hal ini, Anda perlu menghapus perangkat dari array RAID perangkat lunak:
# mdadm /dev /md0 - -remove /dev /sdc1
Kemudian Anda dapat secara fisik menghapusnya dari mesin dan menggantinya dengan bagian cadangan (/dev/sdd, dimana partisi tipe fd telah dibuat sebelumnya):
# mdadm -manajemen /dev /md0 --add /dev /sdd1
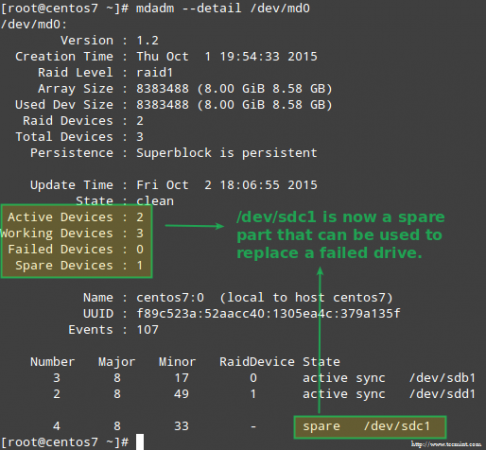
Beruntung bagi kami, sistem akan secara otomatis mulai membangun kembali array dengan bagian yang baru saja kami tambahkan. Kita bisa menguji ini dengan menandai /dev/sdb1 sebagai salah, menghapusnya dari array, dan memastikan file itu tecmint.txt masih dapat diakses di /mnt/raid1:
# mdadm ---detail /dev /md0 # mount | grep raid1 # ls -l /mnt /raid1 | grep tecmint # cat/mnt/raid1/tecmint.txt
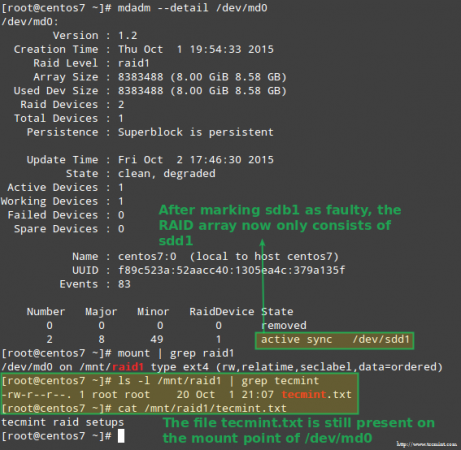 Konfirmasikan pembangunan kembali array serangan
Konfirmasikan pembangunan kembali array serangan Gambar di atas jelas menunjukkan bahwa setelah menambahkan /dev/sdd1 ke array sebagai pengganti untuk /dev/sdc1, pembangunan kembali data secara otomatis dilakukan oleh sistem tanpa intervensi pada bagian kami.
Meskipun tidak sepenuhnya diperlukan, merupakan ide bagus untuk memiliki perangkat cadangan yang berguna sehingga proses mengganti perangkat yang rusak dengan drive yang baik dapat dilakukan dalam snap. Untuk melakukan itu, mari kita tambahkan kembali /dev/sdb1 Dan /dev/sdc1:
# mdadm -manajemen /dev /md0 --add /dev /sdb1 # mdadm -manage /dev /md0 --add /dev /sdc1
 Ganti perangkat RAID yang gagal
Ganti perangkat RAID yang gagal Pulih dari kerugian redundansi
Seperti yang dijelaskan sebelumnya, mdadm akan secara otomatis membangun kembali data saat satu disk gagal. Tapi apa yang terjadi jika 2 disk dalam array gagal? Mari kita simulasikan skenario seperti itu dengan menandai /dev/sdb1 Dan /dev/sdd1 sebagai salah:
# Umount /mnt /raid1 # mdadm --Manage --set-faulty /dev /md0 /dev /sdb1 # mdadm --stop /dev /md0 # mdadm-manajemen --set-wauly /dev /md0 /dev / SDD1
Upaya untuk menciptakan kembali array dengan cara yang sama dibuat pada saat ini (atau menggunakan --Asumsikan bersih opsi) dapat mengakibatkan kehilangan data, jadi harus dibiarkan sebagai pilihan terakhir.
Mari kita coba memulihkan data dari /dev/sdb1, Misalnya, menjadi partisi disk yang serupa (/dev/sde1 - Perhatikan bahwa ini mengharuskan Anda membuat partisi tipe fd di dalam /dev/sde sebelum melanjutkan) menggunakan Ddrescue:
# ddrescue -r 2 /dev /sdb1 /dev /sde1
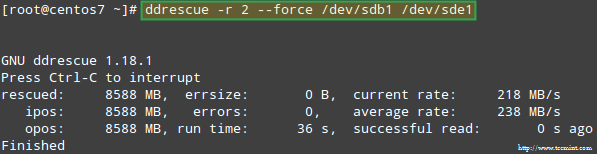 Pulihkan array serangan
Pulihkan array serangan Harap dicatat sampai saat ini, kami belum menyentuh /dev/sdb atau /dev/sdd, partisi yang merupakan bagian dari array serangan.
Sekarang mari kita membangun kembali array menggunakan /dev/sde1 Dan /dev/sdf1:
# mdadm --create /dev /md0-level = mirror--raid-devices = 2 /dev /sd [e-f] 1
Harap dicatat bahwa dalam situasi nyata, Anda biasanya akan menggunakan nama perangkat yang sama seperti dengan array asli, yaitu, /dev/sdb1 Dan /dev/sdc1 Setelah disk yang gagal diganti dengan yang baru.
Dalam artikel ini saya telah memilih untuk menggunakan perangkat tambahan untuk membuat kembali array dengan disk baru dan untuk menghindari kebingungan dengan drive yang gagal asli.
Ketika ditanya apakah akan terus menulis array, ketik Y dan tekan Memasuki. Array harus dimulai dan Anda harus dapat menyaksikan kemajuannya dengan:
# tonton -n 1 kucing /proc /mdstat
Ketika proses selesai, Anda harus dapat mengakses konten serangan Anda:
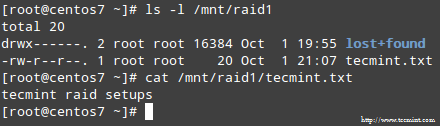 Konfirmasi konten RAID
Konfirmasi konten RAID Ringkasan
Dalam artikel ini kami telah meninjau cara pulih dari SERANGAN kerugian kegagalan dan redundansi. Namun, Anda perlu ingat bahwa teknologi ini adalah solusi penyimpanan dan TIDAK Ganti cadangan.
Prinsip -prinsip yang dijelaskan dalam panduan ini berlaku untuk semua pengaturan RAID, serta konsep yang akan kami liput di panduan berikutnya dan terakhir dari seri ini (RAID MANAJEMEN).
Jika Anda memiliki pertanyaan tentang artikel ini, jangan ragu untuk memberi kami catatan menggunakan formulir komentar di bawah ini. Kami menantikan kabar dari Anda!
- « Cara Mendapatkan Informasi Perangkat Keras dengan Perintah DMIDECODE di Linux
- Powerline - Menambahkan garis status yang kuat dan meminta ke VIM Editor dan Bash Terminal »