

Cara menginstal spark di rhel 8
- 1252
- 321
- Dominick Barton
Apache Spark adalah sistem komputasi terdistribusi. Ini terdiri dari master dan satu atau lebih budak, di mana master mendistribusikan pekerjaan di antara para budak, sehingga memberikan kemampuan untuk menggunakan banyak komputer kita untuk mengerjakan satu tugas. Orang bisa menebak bahwa ini memang merupakan alat yang ampuh di mana tugas membutuhkan perhitungan besar untuk diselesaikan, tetapi dapat dibagi menjadi potongan -potongan yang lebih kecil dari langkah -langkah yang dapat didorong ke budak untuk dikerjakan. Setelah cluster kami berjalan dan berjalan, kami dapat menulis program untuk menjalankannya di Python, Java, dan Scala.
Dalam tutorial ini kami akan mengerjakan satu mesin yang menjalankan Red Hat Enterprise Linux 8, dan akan menginstal Spark Master dan Slave ke mesin yang sama, tetapi perlu diingat bahwa langkah -langkah yang menggambarkan pengaturan budak dapat diterapkan pada sejumlah komputer, dengan demikian menciptakan cluster nyata yang dapat memproses beban kerja yang berat. Kami juga akan menambahkan file unit yang diperlukan untuk manajemen, dan menjalankan contoh sederhana terhadap cluster yang dikirimkan dengan paket terdistribusi untuk memastikan sistem kami beroperasi.
Dalam tutorial ini Anda akan belajar:
- Cara menginstal spark master dan slave
- Cara menambahkan file unit systemd
- Cara memverifikasi koneksi master-slave yang berhasil
- Cara menjalankan contoh pekerjaan sederhana di cluster
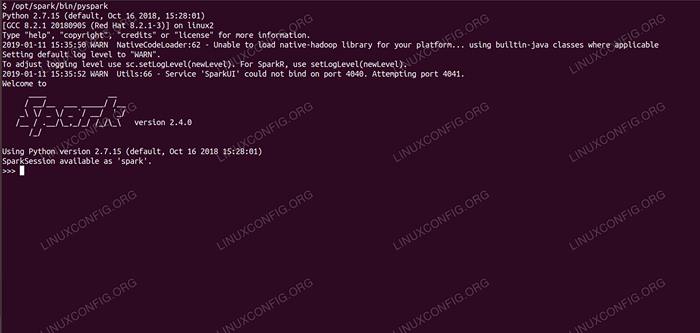
Percikan shell dengan pyspark. Persyaratan dan konvensi perangkat lunak yang digunakan
| Kategori | Persyaratan, konvensi atau versi perangkat lunak yang digunakan |
|---|---|
| Sistem | Red Hat Enterprise Linux 8 |
| Perangkat lunak | Apache Spark 2.4.0 |
| Lainnya | Akses istimewa ke sistem Linux Anda sebagai root atau melalui sudo memerintah. |
| Konvensi | # - mensyaratkan perintah linux yang diberikan untuk dieksekusi dengan hak istimewa root baik secara langsung sebagai pengguna root atau dengan menggunakan sudo memerintah$ - mensyaratkan perintah Linux yang diberikan untuk dieksekusi sebagai pengguna biasa |
Cara menginstal spark di redhat 8 instruksi langkah demi langkah
Apache Spark berjalan di JVM (Java Virtual Machine), jadi instalasi Java 8 yang berfungsi diperlukan untuk aplikasi yang dapat dijalankan. Selain itu, ada beberapa kerang yang dikirimkan di dalam paket, salah satunya Pyspark, cangkang berbasis ularin. Untuk bekerja dengan itu, Anda juga perlu diinstal dan diatur Python 2.
- Untuk mendapatkan URL paket terbaru Spark, kita perlu mengunjungi situs Download Spark. Kita perlu memilih cermin terdekat dengan lokasi kita, dan menyalin URL yang disediakan oleh situs unduhan. Ini juga berarti bahwa URL Anda mungkin berbeda dari contoh di bawah ini. Kami akan menginstal paket di bawah
/memilih/, Jadi kami memasukkan direktori sebagaiakar:# CD /Opt
Dan memberi makan URL Aquired untuk
wgetuntuk mendapatkan paket:# wget https: // www-eu.Apache.org/dist/spark/spark-2.4.0/Spark-2.4.0-Bin-Hadoop2.7.tgz
- Kami akan membongkar tarball:
# tar -xvf spark -2.4.0-Bin-Hadoop2.7.tgz
- Dan membuat symlink untuk membuat jalan kita lebih mudah diingat dalam langkah selanjutnya:
# ln -s /opt /spark -2.4.0-Bin-Hadoop2.7 /opt /spark
- Kami membuat pengguna yang tidak istimewa yang akan menjalankan kedua aplikasi, master dan slave:
# UserAdd Spark
Dan mengaturnya sebagai pemilik keseluruhan
/Opt/Sparkdirektori, rekursif:# chown -r spark: spark /opt /spark*
- Kami membuat a
Systemdfile unit/etc/systemd/system/spark-master.melayaniUntuk layanan master dengan konten berikut:
Menyalin[Unit] Deskripsi = Apache Spark Master After = Network.Target [layanan] type = forking user = spark group = spark execStart =/opt/spark/sbin/start-master.SH execstop =/opt/spark/sbin/stop-master.sh [install] wantedby = multi-pengguna.targetDan juga satu untuk layanan budak yang akan terjadi
/etc/systemd/system/spark-slave.melayani.melayanidengan isi di bawah ini:
Menyalin[Unit] description = Apache Spark Slave After = Network.target [layanan] type = forking user = spark group = spark execstart =/opt/spark/sbin/start-slave.sh spark: // rhel8lab.LinuxConfig.org: 7077 execstop =/opt/spark/sbin/stop-slave.sh [install] wantedby = multi-pengguna.targetPerhatikan URL percikan yang disorot. Ini dibangun dengan
Spark: //: 7077, Dalam hal ini mesin lab yang akan menjalankan master memiliki nama hostRHEL8LAB.LinuxConfig.org. Nama tuan Anda akan berbeda. Setiap budak harus dapat menyelesaikan nama host ini, dan mencapai master di port yang ditentukan, yang merupakan port7077secara default. - Dengan file layanan yang ada, kita perlu bertanya
Systemduntuk membaca kembali mereka:# Systemctl Daemon-reload
- Kita bisa memulai spark master kita
Systemd:# systemctl mulai spark-master.melayani
- Untuk memverifikasi master kami berjalan dan fungsional, kami dapat menggunakan status SystemD:
# Systemctl Status Spark-Master.Layanan Spark-Master.Layanan - Apache Spark Master Loaded: Loaded (/etc/systemd/system/spark -master.melayani; dengan disabilitas; Preset Vendor: Dinonaktifkan) Aktif: Aktif (Berlari) Sejak Jumat 2019-01-11 16:30:03 CET; Proses 53 menit yang lalu: 3308 execstop =/opt/spark/sbin/stop-master.sh (kode = keluar, status = 0/sukses) Proses: 3339 execStart =/opt/spark/sbin/start-master.sh (kode = keluar, status = 0/sukses) PID utama: 3359 (java) Tugas: 27 (Batas: 12544) Memori: 219.3M cgroup: /sistem.Iris/Spark-Master.Layanan 3359/usr/lib/jvm/java-1.8.0-OPENJDK-1.8.0.181.B13-9.EL8.x86_64/jre/bin/java -cp/opt/spark/conf/:/opt/spark/guci/* -xmx1g org.Apache.percikan.menyebarkan.menguasai.Master - -host […] 11 Jan 16:30:00 RHEL8LAB.LinuxConfig.org Systemd [1]: Memulai Apache Spark Master… 11 Jan 16:30:00 RHEL8LAB.LinuxConfig.org start-master.sh [3339]: start org.Apache.percikan.menyebarkan.menguasai.Master, Logging to/Opt/Spark/Logs/Spark-Spark-Org.Apache.percikan.menyebarkan.menguasai.Master-1 […]
Baris terakhir juga menunjukkan logfile utama master, yang ada di
logDirektori di bawah Direktori Basis Spark,/Opt/Sparkdalam kasus kami. Dengan melihat ke file ini, kita akan melihat garis pada akhir yang mirip dengan contoh di bawah ini:2019-01-11 14:45:28 Info Master: 54-Saya telah terpilih sebagai pemimpin! Negara Baru: Hidup
Kita juga harus menemukan garis yang memberi tahu kita di mana antarmuka utama mendengarkan:
2019-01-11 16:30:03 Info Utils: 54-Berhasil Memulai Layanan 'MasterUi' di Port 8080
Jika kita mengarahkan browser ke port mesin host
8080, Kita harus melihat halaman status master, tanpa pekerja yang terpasang saat ini.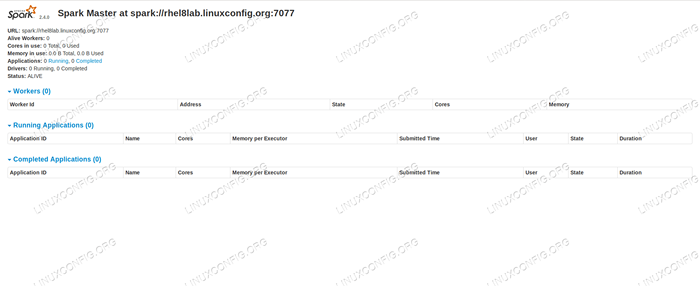 Halaman Status Status Master Spark Tanpa Pekerja Terlampir.
Halaman Status Status Master Spark Tanpa Pekerja Terlampir. Perhatikan baris URL di halaman Status Spark Master. Ini adalah URL yang sama yang perlu kita gunakan untuk file unit setiap budak yang kami buat
Langkah 5.
Jika kami menerima pesan kesalahan "koneksi yang ditolak" di browser, kami mungkin perlu membuka port di firewall:# firewall-cmd --zone = public --add-port = 8080/tcp-Sukses Permanent # firewall-cmd-Reload Success
- Tuan kami sedang berlari, kami akan melampirkan budak untuk itu. Kami memulai layanan budak:
# Systemctl Mulai Spark-Slave.melayani
- Kami dapat memverifikasi bahwa budak kami berjalan dengan SystemD:
# Systemctl Status Spark-Slave.layanan spark-slave.Layanan - Apache Spark Slave dimuat: dimuat (/etc/systemd/system/spark -slave.melayani; dengan disabilitas; Preset Vendor: Dinonaktifkan) Aktif: Aktif (Berlari) Sejak Jumat 2019-01-11 16:31:41 CET; 1H 3MIN AGO PROSES: 3515 EXECSTOP =/OPT/SPARK/SBIN/STOP-SLAVE.sh (kode = keluar, status = 0/sukses) Proses: 3537 execStart =/opt/spark/sbin/start-slave.sh spark: // rhel8lab.LinuxConfig.org: 7077 (kode = keluar, status = 0/sukses) PID Utama: 3554 (java) Tugas: 26 (Batas: 12544) Memori: 176.1m cgroup: /sistem.Iris/Spark-Slave.Layanan 3554/usr/lib/jvm/java-1.8.0-OPENJDK-1.8.0.181.B13-9.EL8.x86_64/jre/bin/java -cp/opt/spark/conf/:/opt/spark/guci/* -xmx1g org.Apache.percikan.menyebarkan.pekerja.Pekerja […] 11 Jan 16:31:39 Rhel8lab.LinuxConfig.org Systemd [1]: Memulai Apache Spark Slave… 11 Jan 16:31:39 RHEL8LAB.LinuxConfig.org start-slave.sh [3537]: start org.Apache.percikan.menyebarkan.pekerja.Pekerja, Logging to/Opt/Spark/Logs/Spark-Lepar […]
Output ini juga menyediakan jalur ke logfile budak (atau pekerja), yang akan berada di direktori yang sama, dengan "pekerja" atas namanya. Dengan memeriksa file ini, kita akan melihat sesuatu yang mirip dengan output di bawah ini:
2019-01-11 14:52:23 Info Pekerja: 54-Menghubungkan ke Master Rhel8Lab.LinuxConfig.org: 7077… 2019-01-11 14:52:23 Info Contexthandler: 781-Mulai o.S.J.S.Servletcontexthandler@62059f4a /metrik/json, null, tersedia,@spark 2019-01-11 14:52:23 Info TransportClientFactory: 267-Berhasil dibuat koneksi ke rhel8lab.LinuxConfig.org/10.0.2.15: 7077 Setelah 58 ms (0 ms dihabiskan di bootstraps) 2019-01-11 14:52:24 Pekerja info: 54-Berhasil terdaftar dengan master spark: // rhel8lab.LinuxConfig.org: 7077
Ini menunjukkan bahwa pekerja berhasil terhubung ke master. Dalam logfile yang sama ini kita akan menemukan garis yang memberi tahu kita URL bahwa pekerja sedang mendengarkan:
2019-01-11 14:52:23 Info WorkerWebUI: 54-WorkerWebUI terikat ke 0.0.0.0, dan dimulai di http: // rhel8lab.LinuxConfig.org: 8081
Kami dapat mengarahkan browser kami ke halaman status pekerja, di mana master itu terdaftar.
 Halaman Status Pekerja BERPARIK, terhubung ke Master.
Halaman Status Pekerja BERPARIK, terhubung ke Master.
Di The Master's Logfile, garis verifikasi akan muncul:
2019-01-11 14:52:24 Info Master: 54-Mendaftar Pekerja 10.0.2.15: 40815 dengan 2 core, 1024.0 MB RAM
Jika kita memuat ulang halaman status master sekarang, pekerja juga akan muncul di sana, dengan tautan ke halaman statusnya.
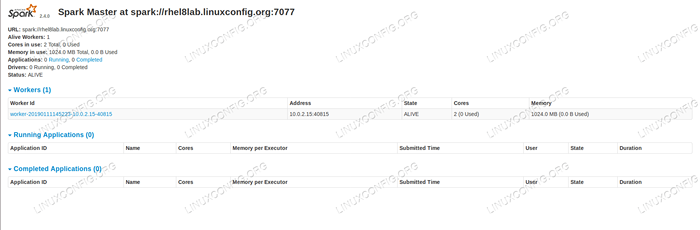 Halaman status master spark dengan satu pekerja terlampir.
Halaman status master spark dengan satu pekerja terlampir. Sumber -sumber ini memverifikasi bahwa cluster kami terpasang dan siap untuk bekerja.
- Untuk menjalankan tugas sederhana di cluster, kami menjalankan salah satu contoh yang dikirimkan dengan paket yang kami unduh. Pertimbangkan TextFile sederhana berikut
/opt/spark/tes.mengajukan:
MenyalinLine1 Word1 Word2 Word3 Line2 Word1 Line3 Word1 Word2 Word3 Word4Kami akan mengeksekusi
jumlah kata.pyContoh di atasnya yang akan menghitung kejadian setiap kata dalam file. Kita bisa menggunakanpercikanPengguna, tidakakarhak istimewa diperlukan.$/opt/spark/bin/spark-submit/opt/spark/contoh/src/main/python/wordcount.py/opt/spark/test.File 2019-01-11 15:56:57 Info SparkContext: 54-Aplikasi yang Dikirim: PythonwordCount 2019-01-11 15:56:57 Info SecurityManager: 54-Mengubah tampilan ACL ke: Spark 2019-01-11 15:56: 57 Info SecurityManager: 54 - Mengubah Modifikasi ACLS menjadi: Spark […]
Saat tugas dijalankan, output panjang disediakan. Dekat dengan akhir output, hasilnya ditampilkan, cluster menghitung informasi yang diperlukan:
2019-01-11 15:57:05 Info Dagscheduler: 54-Pekerjaan 0 Selesai: Kumpulkan AT/OPT/SPARK/Contoh/SRC/Main/Python/WordCount.py: 40, mengambil 1.619928 s Line3: 1 Line2: 1 Line1: 1 Word4: 1 Word1: 3 Word3: 2 Word2: 2 […]
Dengan ini kita telah melihat Apache Spark kami sedang beraksi. Node slave tambahan dapat diinstal dan dilampirkan untuk skala daya komputasi cluster kami.
Tutorial Linux Terkait:
- Cara membuat cluster kubernetes
- Instalasi Oracle Java di Ubuntu 20.04 FOSSA FOSSA Linux
- Hal -hal yang harus diinstal pada ubuntu 20.04
- Cara menginstal java di manjaro linux
- Linux: Instal Java
- Cara menginstal kubernet di ubuntu 20.04 FOSSA FOSSA Linux
- Cara menginstal kubernet di ubuntu 22.04 Jammy Jellyfish…
- Ubuntu 20.04 Hadoop
- Pengantar Otomatisasi Linux, Alat dan Teknik
- Ubuntu 20.04 WordPress dengan Instalasi Apache