

Cara Menginstal Cluster Elasticsearch (Multi Node) di CentOS/RHEL, Ubuntu & Debian

- 4215
- 337
- Simon Cormier
Elasticsearch adalah open source fleksibel dan kuat, pencarian real-time dan mesin analitik terdistribusi. Menggunakan satu set API sederhana, ini memberikan kemampuan untuk pencarian teks lengkap. Pencarian elastis tersedia secara bebas di bawah lisensi Apache 2, yang memberikan sebagian besar fleksibilitas.
Artikel ini akan membantu Anda untuk mengkonfigurasi klaster multi -simpul Elasticsearch di Centos, RHEL, Ubuntu dan Debian Systems. Di Elasticsearch Multi Node Cluster hanya mengkonfigurasi beberapa kelompok simpul tunggal dengan nama kluster yang sama di jaringan yang sama.
Network Scenerio
Kami memiliki tiga server dengan IPS dan nama host berikut. Semua server berjalan di LAN yang sama dan memiliki akses penuh ke server satu sama lain menggunakan IP dan hostname keduanya.
192.168.10.101 Node_1 192.168.10.102 Node_2 192.168.10.103 Node_3
Verifikasi java (semua node)
Java adalah persyaratan utama untuk menginstal Elasticsearch. Jadi pastikan Anda memasang java di semua node.
# java -version java versi "1.8.0_31 "Java (TM) SE Runtime Environment (Build 1.8.0_31-B13) Java Hotspot (TM) 64-bit Server VM (Build 25.31-B07, mode campuran)
Jika Anda tidak menginstal Java pada sistem node apa pun, gunakan salah satu tautan berikut untuk menginstalnya terlebih dahulu.
Instal Java 8 di Centos/Rhel 7/6/5
Instal Java 8 di Ubuntu
Unduh Elasticsearch (semua node)
Sekarang unduh Arsip Elasticsearch terbaru di semua sistem node dari halaman unduhan resminya. Pada saat pembaruan terakhir artikel ini Elasticsearch 1.4.2 Versi adalah versi terbaru yang tersedia untuk diunduh. Gunakan perintah berikut untuk mengunduh Elasticsearch 1.4.2.
$ wget https: // unduh.Elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.2.ter.GZ
Sekarang ekstrak Elasticsearch pada semua sistem node.
$ tar xzf elasticsearch-1.4.2.ter.GZ
Konfigurasikan Elasticsearch
Sekarang kita perlu mengatur Elasticsearch di semua sistem node. Elasticsearch menggunakan "Elasticsearch" sebagai nama kluster default. Kami menyarankan untuk mengubahnya sesuai percakapan penamaan Anda.
$ MV Elasticsearch-1.4.2/usr/share/elasticsearch $ cd/usr/share/elasticsearch
Untuk mengubah cluster bernama edit Config/Elasticsearch.YML file di setiap node dan perbarui nilai berikut. Nama simpul dihasilkan secara dinamis, tetapi untuk menjaga nama yang tetap ramah pengguna tetap juga.
Di node_1
Edit Elasticsearch Cluster Configuration di Node_1 (192.168.10.101) sistem.
$ vim config/elasticsearch.YML
gugus.Nama: node tecadmincluster.Nama: "Node_1"
Di node_2
Edit Elasticsearch Cluster Configuration di Node_2 (192.168.10.102) sistem.
$ vim config/elasticsearch.YML
gugus.Nama: node tecadmincluster.Nama: "Node_2"
Di node_3
Edit Elasticsearch Cluster Configuration di Node_3 (192.168.10.103) Sistem.
$ vim config/elasticsearch.YML
gugus.Nama: node tecadmincluster.Nama: "Node_3"
Instal Elasticsearch-Head Plugin (semua node)
Elasticsearch-Head adalah ujung depan web untuk menjelajah dan berinteraksi dengan cluster pencarian elastis. Gunakan perintah berikut untuk menginstal plugin ini di semua sistem node.
$ bin/plugin-instal mobz/elasticsearch-head
Start Elasticsearch Cluster (semua node)
Karena pengaturan klaster Elasticsearch telah selesai. Biarkan cluster Elasticsearch menggunakan perintah berikut di semua node.
$ ./bin/elasticsearch &
Secara default Elasticserch Listen di port 9200 dan 9300. Jadi sambungkan ke Node_1 Di port 9200 seperti URL berikut, Anda akan melihat ketiga node di cluster Anda.
http: // node_1: 9200/_plugin/head/
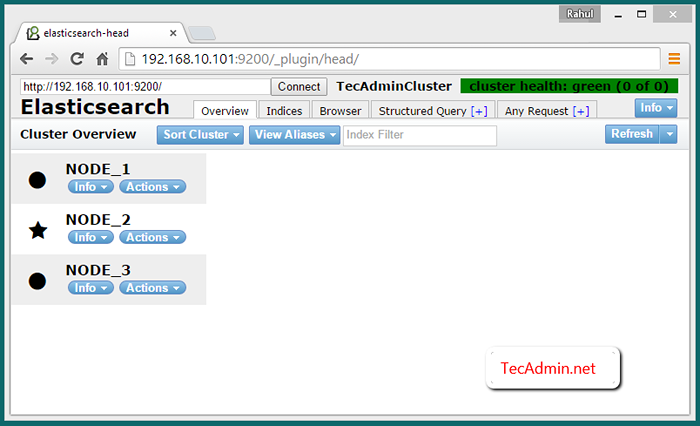
Verifikasi kluster multi -simpul
Untuk memverifikasi bahwa cluster berfungsi dengan baik. Masukkan beberapa data dalam satu node dan jika data yang sama tersedia di node lain, itu berarti cluster berfungsi dengan baik.
Masukkan data di Node_1
Untuk memverifikasi cluster, buat ember di Node_1 dan tambahkan beberapa data.
$ curl -xput http: // node_1: 9200/mybucket $ curl -xput 'http: // node_1: 9200/mybucket/user/rahul' -d '"nama": "Rahul kumar"'
$ curl -xput 'http: // node_1: 9200/mybucket/post/1' -d '"user": "rahul", "postdate": "01-16-2015", "body": "menambahkan data di elasticsearch cluster "," title ":" Elasticsearch Cluster Test " '
Cari data di semua node
Sekarang cari data yang sama dari Node_2 Dan Node_3 dan periksa apakah data yang sama direplikasi ke node cluster lainnya. Sesuai perintah di atas kami telah membuat pengguna bernama Rahul dan menambahkan beberapa data di sana. Jadi gunakan perintah berikut untuk mencari data yang terkait dengan pengguna Rahul.
$ curl 'http: // node_1: 9200/mybucket/post/_search?Q = Pengguna: Rahul & Pretty = true '$ curl' http: // node_2: 9200/mybucket/post/_search?Q = Pengguna: Rahul & Pretty = true '$ curl' http: // node_3: 9200/mybucket/post/_search?Q = Pengguna: Rahul & Pretty = True '
dan Anda akan mendapatkan hasil seperti di bawah ini untuk semua perintah di atas.
"Take": 69, "Timed_out": false, "_shards": "Total": 5, "Sukses": 5, "Gagal": 0, "Hits": "Total": 1, "Max_Score ": 1.0, "Hits": ["_index": "mybucket", "_type": "post", "_id": "1", "_score": 1.0, "_source": "user": "rahul", "postdate": "01-16-2015", "body": "Menambahkan data di elasticsearch cluster", "title": "Elasticsearch Cluster Test" ]
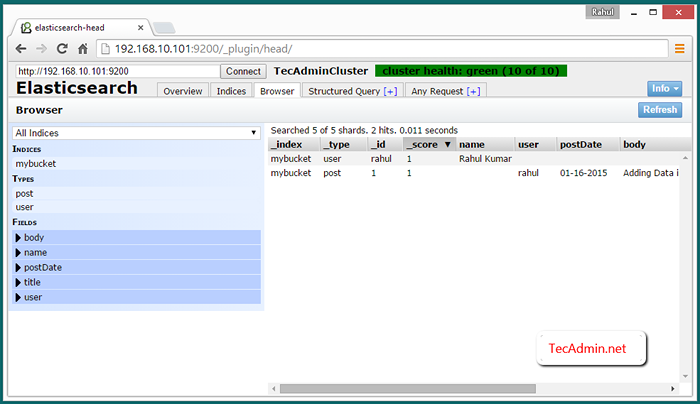
Lihat Data Cluster di Browser Web
Untuk melihat data tentang Elasticsearch Cluster Access of Elasticsearch-Head Plugin menggunakan salah satu cluster IP di bawah URL di bawah ini. Kemudian klik Browser tab.
http: // node_1: 9200/_plugin/head/
- « Cara menggunakan perintah systemctl untuk mengelola layanan systemd
- Menambahkan Epel Repositori Ekstra dan Remi pada sistem berbasis RHEL »