

Cara Menginstal Apache Hadoop di Ubuntu 22.04

- 1864
- 80
- John Ratke
Memahami data yang tidak terstruktur dan menganalisis sejumlah besar data adalah permainan bola yang berbeda saat ini. Maka, bisnis telah menggunakan Apache Hadoop dan teknologi terkait lainnya untuk mengelola data yang tidak terstruktur dengan lebih efisien. Bukan hanya bisnis tetapi juga individu menggunakan Apache Hadoop untuk berbagai tujuan, seperti menganalisis kumpulan data besar atau membuat situs web yang dapat memproses kueri pengguna. Namun, menginstal Apache Hadoop di Ubuntu mungkin tampak seperti tugas yang sulit bagi pengguna yang baru di dunia server Linux. Untungnya, Anda tidak perlu menjadi administrator sistem yang berpengalaman untuk menginstal Apache Hadoop di Ubuntu.
Panduan instalasi langkah demi langkah berikut akan membuat Anda melalui seluruh proses dari mengunduh perangkat lunak untuk mengonfigurasi server dengan mudah. Di artikel ini, kami akan menjelaskan cara menginstal Apache Hadoop di Ubuntu 22.04 Sistem LTS. Ini juga dapat digunakan untuk versi Ubuntu lainnya.
Langkah 1: Instal Java Development Kit
Java adalah komponen yang diperlukan dari Apache Hadoop, jadi Anda perlu mengunduh dan menginstal kit pengembangan Java di semua node di jaringan Anda di mana Hadoop akan diinstal. Anda dapat mengunduh JRE atau JDK. Jika Anda hanya ingin menjalankan Hadoop, maka JRE sudah cukup, tetapi jika Anda ingin membuat aplikasi yang berjalan di Hadoop, maka Anda harus menginstal JDK. Versi terbaru Java yang didukung Hadoop adalah Java 8 dan 11. Anda dapat memverifikasi ini di situs web Apache dan mengunduh versi Java yang relevan tergantung pada OS Anda.
- Repositori Ubuntu default berisi Java 8 dan Java 11 keduanya. Gunakan perintah berikut untuk menginstalnya.
sudo apt update && sudo apt instal openjdk-11-jdk - Setelah Anda berhasil menginstalnya, periksa versi Java saat ini:
java -version Periksa versi java
Periksa versi java - Anda dapat menemukan lokasi direktori java_home dengan menjalankan perintah berikut. Itu akan diperlukan terbaru dalam artikel ini.
dirname $ (dirname $ (readlink -f $ (yang java)))) Periksa lokasi java_home
Periksa lokasi java_home
Langkah 2: Buat pengguna untuk Hadoop
Semua komponen Hadoop akan berjalan sebagai pengguna yang Anda buat untuk Apache Hadoop, dan pengguna juga akan digunakan untuk masuk ke antarmuka web Hadoop. Anda dapat membuat akun pengguna baru dengan perintah "sudo" atau Anda dapat membuat akun pengguna dengan izin "root". Akun pengguna dengan izin root lebih aman tetapi mungkin tidak nyaman bagi pengguna yang tidak terbiasa dengan baris perintah.
- Jalankan perintah berikut untuk membuat pengguna baru dengan nama "Hadoop":
Sudo Adduser Hadoop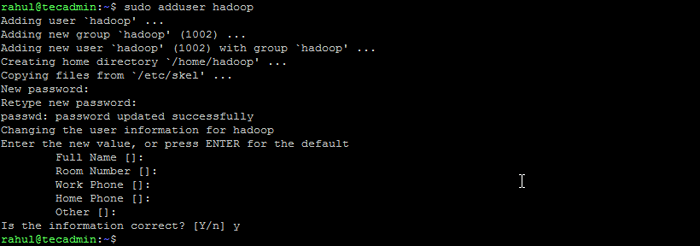 Buat pengguna Hadoop
Buat pengguna Hadoop - Beralih ke pengguna Hadoop yang baru dibuat:
Su - Hadoop - Sekarang konfigurasikan akses SSH tanpa kata sandi untuk pengguna Hadoop yang baru dibuat. Hasilkan keypair ssh terlebih dahulu:
ssh -keygen -t RSA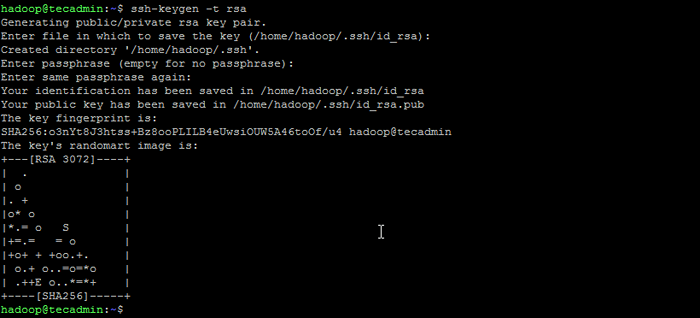 Menghasilkan pasangan kunci ssh
Menghasilkan pasangan kunci ssh - Salin kunci publik yang dihasilkan ke file kunci resmi dan atur izin yang tepat:
kucing ~/.ssh/id_rsa.pub >> ~//.ssh/otorisasi_keysChmod 640 ~/.ssh/otorisasi_keys - Sekarang coba ssh ke localhost.
SSH LocalhostAnda akan diminta untuk mengotentikasi host dengan menambahkan kunci RSA ke host yang dikenal. Ketik ya dan tekan enter untuk mengotentikasi localhost:
 Hubungkan SSH ke LocalHost
Hubungkan SSH ke LocalHost
Langkah 3: Instal Hadoop di Ubuntu
Setelah Anda menginstal Java, Anda dapat mengunduh Apache Hadoop dan semua komponen terkait, termasuk Hive, Pig, Sqoop, dll. Anda dapat menemukan versi terbaru di halaman unduhan resmi Hadoop. Pastikan untuk mengunduh arsip biner (bukan sumbernya).
- Gunakan perintah berikut untuk mengunduh Hadoop 3.3.4:
wget https: // dlcdn.Apache.org/hadoop/common/hadoop-3.3.4/Hadoop-3.3.4.ter.GZ - Setelah Anda mengunduh file, Anda dapat membuka ritsleting ke folder di hard drive Anda.
TAR XZF HADOOP-3.3.4.ter.GZ - Ubah nama folder yang diekstraksi untuk menghapus informasi versi. Ini adalah langkah opsional, tetapi jika Anda tidak ingin mengganti nama, maka sesuaikan jalur konfigurasi yang tersisa.
MV Hadoop-3.3.4 Hadoop - Selanjutnya, Anda perlu mengkonfigurasi variabel lingkungan Hadoop dan Java di sistem Anda. Buka ~/.File Bashrc di editor teks favorit Anda:
nano ~/.BashrcTambahkan baris di bawah ini ke file. Anda dapat menemukan lokasi java_home dengan berlari
Ekspor java_home =/usr/lib/jvm/java-11-opanjdk-amd64 ekspor hadoop_home =/home/hadoop/hadoop hadoop_install = $ hadoop_home hadoop_home = hadoop_home hadoop_home hadoop_home = hadoop hadoop_home hadoop hadoop_home hadoop_home $ HADOOP_HOME EKSPOR HADOOP_COMMON_LIB_NATIF_DIR = $ hadoop_home/lib/jalur ekspor asli = $ path: $ hadoop_home/sbin: $ hadoop_home/bin ekspor hadoop_opts = "-djava.perpustakaan.path = $ hadoop_home/lib/asli "dirname $ (dirname $ (readlink -f $ (yang java))))Perintah di terminal.12345678910 export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64export HADOOP_HOME=/home/hadoop/hadoopexport HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport HADOOP_YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/ lib/path nativeExport = $ path: $ hadoop_home/sbin: $ hadoop_home/binexport hadoop_opts = "-djava.perpustakaan.path = $ hadoop_home/lib/asli " Simpan file dan tutup.
- Muat konfigurasi di atas di lingkungan saat ini.
Sumber ~/.Bashrc - Anda juga perlu mengkonfigurasi Java_home di dalam Hadoop-env.SH mengajukan. Edit file variabel lingkungan Hadoop di editor teks:
nano $ hadoop_home/etc/hadoop/hadoop-env.SHCari "Ekspor Java_Home" dan konfigurasinya dengan nilai yang ditemukan pada Langkah 1. Lihat tangkapan layar di bawah ini:
 Atur java_home
Atur java_homeSimpan file dan tutup.
Langkah 4: Mengkonfigurasi Hadoop
Berikutnya adalah untuk mengkonfigurasi file konfigurasi Hadoop yang tersedia di bawah direktori ETC.
- Pertama, Anda perlu membuat namenode Dan datanode Direktori di dalam direktori rumah pengguna Hadoop. Jalankan perintah berikut untuk membuat kedua direktori:
mkdir -p ~/hadoopdata/hdfs/namenode, datasode - Selanjutnya, edit situs inti.xml File dan perbarui dengan nama host sistem Anda:
nano $ hadoop_home/etc/hadoop/core-situs.xmlUbah nama berikut sesuai nama host sistem Anda:
FS.defaultfs hdfs: // localhost: 9000123456 FS.defaultfs hdfs: // localhost: 9000 Simpan dan tutup file.
- Kemudian, edit HDFS-SITE.xml mengajukan:
nano $ hadoop_home/etc/hadoop/hdfs-site.xmlUbah jalur direktori namenode dan datanode seperti yang ditunjukkan di bawah ini:
dfs.Replikasi 1 DFS.nama.File dir: /// home/hadoop/hadoopdata/hdfs/namenode dfs.data.File dir: /// home/hadoop/hadoopdata/hdfs/datanode12345678910111213141516 dfs.Replikasi 1 DFS.nama.File dir: /// home/hadoop/hadoopdata/hdfs/namenode dfs.data.File dir: /// home/hadoop/hadoopdata/hdfs/datanode Simpan dan tutup file.
- Kemudian, edit Situs Mapred.xml mengajukan:
nano $ hadoop_home/etc/hadoop/mapred-site.xmlBuat perubahan berikut:
Mapreduce.kerangka.Nama benang123456 Mapreduce.kerangka.Nama benang Simpan dan tutup file.
- Kemudian, edit situs benang.xml mengajukan:
nano $ hadoop_home/etc/hadoop/site benang.xmlBuat perubahan berikut:
benang.NodeManager.aux-services mapreduce_shuffle123456 benang.NodeManager.aux-services mapreduce_shuffle Simpan file dan tutup.
Langkah 5: Mulai Hadoop Cluster
Sebelum memulai klaster Hadoop. Anda perlu memformat namenode sebagai pengguna Hadoop.
- Jalankan perintah berikut untuk memformat namenode Hadoop:
HDFS Namenode -FormatSetelah direktori namenode berhasil diformat dengan sistem file HDFS, Anda akan melihat pesannya “Direktori Penyimpanan/Rumah/Hadoop/HadoopData/HDFS/Namenode telah berhasil diformat“.
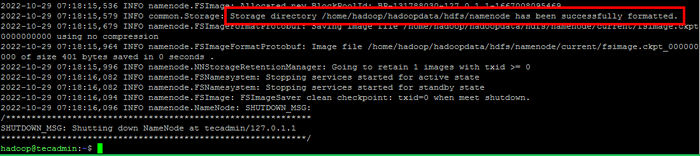 Format namenode
Format namenode - Kemudian mulai kluster hadoop dengan perintah berikut.
start-all.SH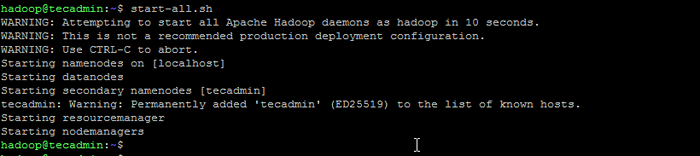 Mulai Layanan Hadoop
Mulai Layanan Hadoop - Setelah semua layanan dimulai, Anda dapat mengakses Hadoop di: http: // localhost: 9870

- Dan halaman aplikasi Hadoop tersedia di http: // localhost: 8088

Kesimpulan
Menginstal Apache Hadoop di Ubuntu bisa menjadi tugas yang sulit bagi pemula, terutama jika mereka hanya mengikuti instruksi dalam dokumentasi. Untungnya, artikel ini menyediakan panduan langkah demi langkah yang akan membantu Anda menginstal Apache Hadoop di Ubuntu dengan mudah. Yang harus Anda lakukan adalah mengikuti instruksi yang tercantum dalam artikel ini, dan Anda dapat yakin bahwa instalasi hadoop Anda akan berjalan dan berjalan dalam waktu singkat.