

Cara Menginstal dan Mengatur Apache Spark di Ubuntu/Debian

- 2710
- 648
- Enrique Purdy
Apache Spark adalah kerangka komputasi terdistribusi sumber terbuka yang dibuat untuk memberikan hasil komputasi yang lebih cepat. Ini adalah mesin komputasi dalam memori, yang berarti data akan diproses dalam memori.
Percikan Mendukung berbagai API untuk streaming, pemrosesan grafik, SQL, mllib. Ini juga mendukung Java, Python, Scala, dan R sebagai bahasa yang disukai. Spark sebagian besar diinstal dalam cluster Hadoop tetapi Anda juga dapat menginstal dan mengkonfigurasi Spark dalam mode mandiri.
Di artikel ini, kita akan melihat cara menginstal Apache Spark di dalam Debian Dan Ubuntu-distribusi berbasis.
Instal Java dan Scala di Ubuntu
Untuk memasang Apache Spark Di Ubuntu, Anda harus memilikinya Jawa Dan Scala diinstal di mesin Anda. Sebagian besar distribusi modern dilengkapi dengan java yang diinstal secara default dan Anda dapat memverifikasi menggunakan perintah berikut.
$ java -version
 Periksa versi java di ubuntu
Periksa versi java di ubuntu Jika tidak ada output, Anda dapat menginstal java menggunakan artikel kami tentang cara menginstal java di ubuntu atau cukup menjalankan perintah berikut untuk menginstal java pada distribusi yang berbasis di Ubuntu dan Debian.
$ sudo apt update $ sudo apt menginstal default -jre $ java -version
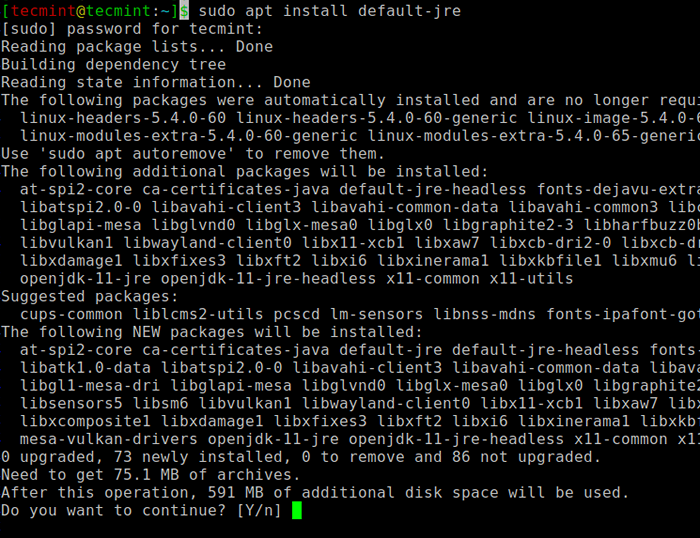 Instal Java di Ubuntu
Instal Java di Ubuntu Selanjutnya, Anda dapat menginstal Scala Dari repositori yang tepat dengan menjalankan perintah berikut untuk mencari Scala dan menginstalnya.
$ sudo aPt Search Scala ⇒ Cari Paket $ Sudo Apt Instal Scala ⇒ Instal Paket
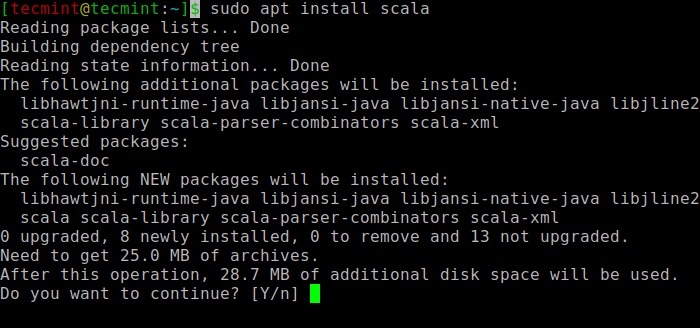 Instal Scala di Ubuntu
Instal Scala di Ubuntu Untuk memverifikasi pemasangan Scala, Jalankan perintah berikut.
$ Scala -Versi Scala Code Runner Versi 2.11.12-Hak Cipta 2002-2017, LAMP/EPFL
Instal Apache Spark di Ubuntu
Sekarang buka halaman unduhan Apache Spark resmi dan ambil versi terbaru (saya.e. 3.1.1) Pada saat penulisan artikel ini. Atau, Anda dapat menggunakan perintah wget untuk mengunduh file secara langsung di terminal.
$ wget https: // apachemirror.Wuchna.com/spark/spark-3.1.1/Spark-3.1.1-bin-hadoop2.7.tgz
Sekarang buka terminal Anda dan beralih ke tempat file yang diunduh Anda ditempatkan dan jalankan perintah berikut untuk mengekstrak file tar Apache Spark Tar.
$ tar -xvzf spark -3.1.1-bin-hadoop2.7.tgz
Akhirnya, pindahkan yang diekstraksi Percikan direktori ke /memilih direktori.
$ sudo mv spark-3.1.1-bin-hadoop2.7 /opt /spark
Konfigurasikan variabel lingkungan untuk percikan
Sekarang Anda harus menetapkan beberapa variabel lingkungan di .Profil file sebelum memulai percikan.
$ echo "ekspor spark_home =/opt/spark" >> ~/.profil $ echo "jalur ekspor = $ path:/opt/spark/bin:/opt/spark/sbin" >> ~//.profil $ echo "Ekspor pyspark_python =/usr/bin/python3" >> ~//.Profil
Untuk memastikan bahwa variabel lingkungan baru ini dapat dijangkau di dalam shell dan tersedia untuk Apache Spark, juga wajib untuk menjalankan perintah berikut untuk menerapkan perubahan terbaru.
$ sumber ~/.Profil
Semua binari terkait percikan untuk memulai dan menghentikan layanan berada di bawah SBIN map.
$ ls -l /opt /spark
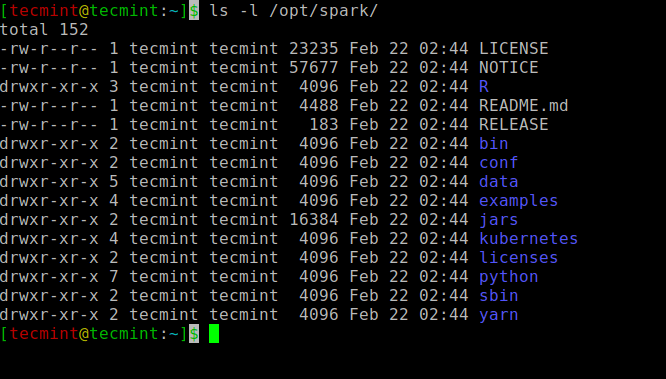 Binari Binari
Binari Binari Mulai Apache Spark di Ubuntu
Jalankan perintah berikut untuk memulai Percikan Layanan Master dan Layanan Budak.
$ start-master.Sh $ start-workers.sh spark: // localhost: 7077
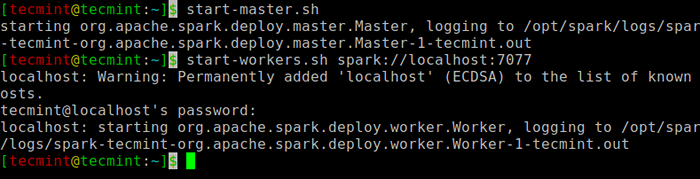 Mulai Layanan Spark
Mulai Layanan Spark Setelah layanan dimulai, kunjungi browser dan ketik halaman percikan Akses URL berikut. Dari halaman, Anda dapat melihat layanan tuan dan budak saya dimulai.
http: // localhost: 8080/atau http: // 127.0.0.1: 8080
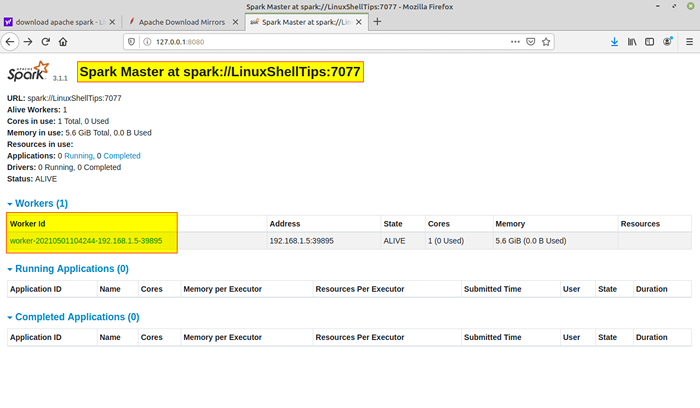 Halaman Web Spark
Halaman Web Spark Anda juga dapat memeriksa apakah Spark-shell berfungsi dengan baik dengan meluncurkan Spark-shell memerintah.
$ spark-shell
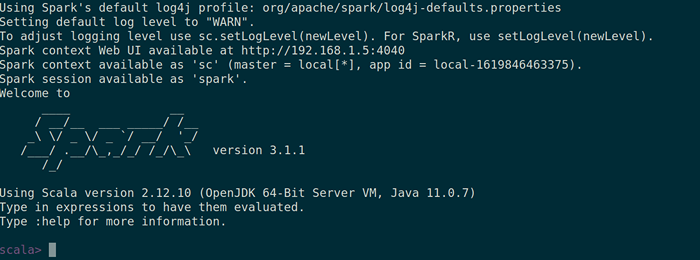 Percikan shell
Percikan shell Itu untuk artikel ini. Kami akan segera menangkap Anda dengan artikel menarik lainnya.
- « LFCA belajar biaya cloud dan penganggaran - Bagian 16
- Cara memantau server linux dan memproses metrik dari browser »