

Cara Menginstal dan Mengkonfigurasi Hadoop di Ubuntu 20.04

- 4832
- 1062
- John Ratke
Hadoop adalah kerangka kerja perangkat lunak yang gratis, open-source, dan berbasis Java yang digunakan untuk penyimpanan dan pemrosesan kumpulan data besar pada kelompok mesin. Menggunakan HDFS untuk menyimpan data dan memproses data ini menggunakan MapReduce. Ini adalah ekosistem alat data besar yang terutama digunakan untuk penambangan data dan pembelajaran mesin.
Apache Hadoop 3.3 dilengkapi dengan perbaikan nyata dan banyak perbaikan bug selama rilis sebelumnya. Ini memiliki empat komponen utama seperti Hadoop Common, HDFS, Benang, dan MapReduce.
Tutorial ini akan menjelaskan kepada Anda cara menginstal dan mengkonfigurasi Apache Hadoop di Ubuntu 20.04 LTS Linux System.
Langkah 1 - Menginstal Java
Hadoop ditulis di Java dan hanya mendukung Java Versi 8. Hadoop Versi 3.3 dan runtime Java 11 yang terbaru juga mendukung Java 8.
Anda dapat menginstal OpenJDK 11 dari repositori apt default:
pembaruan apt sudosudo apt instal openjdk-11-jdk
Setelah diinstal, verifikasi versi Java yang diinstal dengan perintah berikut:
java -version Anda harus mendapatkan output berikut:
Versi OpenJDK "11.0.11 "2021-04-20 Lingkungan Runtime OpenJDK (Build 11.0.11+9-ubuntu-0ubuntu2.20.04) OpenJDK 64-Bit Server VM (Build 11.0.11+9-ubuntu-0ubuntu2.20.04, mode campuran, berbagi)
Langkah 2 - Buat Pengguna Hadoop
Merupakan ide bagus untuk membuat pengguna terpisah untuk menjalankan Hadoop untuk alasan keamanan.
Jalankan perintah berikut untuk membuat pengguna baru dengan nama Hadoop:
Sudo Adduser Hadoop Berikan dan konfirmasi kata sandi baru seperti yang ditunjukkan di bawah ini:
Menambahkan Pengguna 'Hadoop' ... Menambahkan Grup Baru 'Hadoop' (1002) ... Menambahkan Pengguna Baru 'Hadoop' (1002) dengan grup 'Hadoop' ... membuat direktori home '/home/hadoop' ... menyalin file dari '/etc/skel' … Kata Sandi Baru: Retype Kata Sandi Baru: Passwd: Kata Sandi Diperbarui Berhasil Mengubah Informasi Pengguna Untuk Hadoop Masukkan Nilai Baru, atau Tekan Enter untuk Nama Lengkap Default []: Nomor Kamar []: Telepon kerja []: telepon rumah []: Lainnya []: apakah informasinya benar? [Y/n] y
Langkah 3 - Mengkonfigurasi Otentikasi Berbasis Key SSH
Selanjutnya, Anda perlu mengonfigurasi otentikasi SSH tanpa kata sandi untuk sistem lokal.
Pertama, ubah pengguna menjadi Hadoop dengan perintah berikut:
Su - Hadoop Selanjutnya, jalankan perintah berikut untuk menghasilkan pasangan kunci publik dan pribadi:
ssh -keygen -t RSA Anda akan diminta untuk memasukkan nama file. Cukup tekan ENTER untuk menyelesaikan proses:
Menghasilkan pasangan kunci RSA publik/pribadi. Masukkan file untuk menyimpan kunci (/home/hadoop/.ssh/id_rsa): Direktori dibuat '/home/hadoop/.ssh '. Masukkan frasa sandi (kosong tanpa frasa sandi): Masukkan frasa sandi yang sama lagi: Identifikasi Anda telah disimpan di/home/hadoop/.ssh/id_rsa kunci publik Anda telah disimpan di/home/hadoop/.ssh/id_rsa.pub sidik jari kunci adalah: sha256: qsa2syeiswp0hd+uxxxi0j9msorjkdgibkfbm3ejyik [email dilindungi] gambar acak kunci adalah:+--- [RSA 3072] ----+| ... O ++ = = O ++ =.+ | | ... OO++.O | |. oo. B . | | o… + o * . | | = ++ o o s | |.++o+ o | |.+.+ + . o | | o . o * o . | | E + . | +---- [SHA256]-----+
Selanjutnya, tambahkan kunci publik yang dihasilkan dari ID_RSA.pub ke otorisasi_keys dan menetapkan izin yang tepat:
kucing ~/.ssh/id_rsa.pub >> ~//.ssh/otorisasi_keysChmod 640 ~/.ssh/otorisasi_keys
Selanjutnya, verifikasi otentikasi SSH tanpa kata sandi dengan perintah berikut:
SSH Localhost Anda akan diminta untuk mengotentikasi host dengan menambahkan kunci RSA ke host yang dikenal. Ketik ya dan tekan enter untuk mengotentikasi localhost:
Keaslian tuan rumah 'localhost (127.0.0.1) 'tidak bisa didirikan. ECDSA Key Fingerprint adalah SHA256: JFQDVBM3ZTPHUPGD5OMJ4CLVIH6TZIRZ2GD3BDNQGMQ. Apakah Anda yakin ingin terus menghubungkan (ya/tidak/[sidik jari])? Ya
Langkah 4 - Memasang Hadoop
Pertama, ubah pengguna menjadi Hadoop dengan perintah berikut:
Su - Hadoop Selanjutnya, unduh versi terbaru Hadoop menggunakan perintah WGET:
wget https: // unduhan.Apache.org/hadoop/common/hadoop-3.3.0/Hadoop-3.3.0.ter.GZ Setelah diunduh, ekstrak file yang diunduh:
tar -xvzf Hadoop -3.3.0.ter.GZ Selanjutnya, ganti nama direktori yang diekstraksi ke Hadoop:
MV Hadoop-3.3.0 Hadoop Selanjutnya, Anda perlu mengkonfigurasi variabel lingkungan Hadoop dan Java di sistem Anda.
Buka ~/.Bashrc File di editor teks favorit Anda:
nano ~/.Bashrc Tambahkan baris di bawah ini untuk mengajukan. Anda dapat menemukan lokasi java_home dengan berlari dirname $ (dirname $ (readlink -f $ (yang java)))) Perintah di terminal.
Ekspor java_home =/usr/lib/jvm/java-11-opanjdk-amd64 ekspor hadoop_home =/home/hadoop/hadoop hadoop_install = $ hadoop_home hadoop_home = hadoop_home hadoop_home hadoop_home = hadoop hadoop_home hadoop hadoop_home hadoop_home $ HADOOP_HOME EKSPOR HADOOP_COMMON_LIB_NATIF_DIR = $ hadoop_home/lib/jalur ekspor asli = $ path: $ hadoop_home/sbin: $ hadoop_home/bin ekspor hadoop_opts = "-djava.perpustakaan.path = $ hadoop_home/lib/asli "
Simpan dan tutup file. Kemudian, aktifkan variabel lingkungan dengan perintah berikut:
Sumber ~/.Bashrc Selanjutnya, buka file variabel lingkungan Hadoop:
nano $ hadoop_home/etc/hadoop/hadoop-env.SH Sekali lagi atur java_home di lingkungan Hadoop.
Ekspor java_home =/usr/lib/jvm/java-11-openjdk-amd64
Simpan dan tutup file saat Anda selesai.
Langkah 5 - Mengkonfigurasi Hadoop
Pertama, Anda perlu membuat direktori namenode dan data di dalam direktori Hadoop Home:
Jalankan perintah berikut untuk membuat kedua direktori:
mkdir -p ~/hadoopdata/hdfs/namenodemkdir -p ~/hadoopdata/hdfs/datasode
Selanjutnya, edit situs inti.xml File dan perbarui dengan nama host sistem Anda:
nano $ hadoop_home/etc/hadoop/core-situs.xml Ubah nama berikut sesuai nama host sistem Anda:
FS.defaultfs hdfs: // hadoop.tecadmin.com: 9000| 123456 | FS.defaultfs hdfs: // hadoop.tecadmin.com: 9000 |
Simpan dan tutup file. Kemudian, edit HDFS-SITE.xml mengajukan:
nano $ hadoop_home/etc/hadoop/hdfs-site.xml Ubah jalur direktori namenode dan datanode seperti yang ditunjukkan di bawah ini:
dfs.Replikasi 1 DFS.nama.File dir: /// home/hadoop/hadoopdata/hdfs/namenode dfs.data.File dir: /// home/hadoop/hadoopdata/hdfs/datanode| 1234567891011121314151617 | dfs.Replikasi 1 DFS.nama.File dir: /// home/hadoop/hadoopdata/hdfs/namenode dfs.data.File dir: /// home/hadoop/hadoopdata/hdfs/datanode |
Simpan dan tutup file. Kemudian, edit Situs Mapred.xml mengajukan:
nano $ hadoop_home/etc/hadoop/mapred-site.xml Buat perubahan berikut:
Mapreduce.kerangka.Nama benang| 123456 | Mapreduce.kerangka.Nama benang |
Simpan dan tutup file. Kemudian, edit situs benang.xml mengajukan:
nano $ hadoop_home/etc/hadoop/site benang.xml Buat perubahan berikut:
benang.NodeManager.aux-services mapreduce_shuffle| 123456 | benang.NodeManager.aux-services mapreduce_shuffle |
Simpan dan tutup file saat Anda selesai.
Langkah 6 - Mulai Hadoop Cluster
Sebelum memulai klaster Hadoop. Anda perlu memformat namenode sebagai pengguna Hadoop.
Jalankan perintah berikut untuk memformat namenode Hadoop:
HDFS Namenode -Format Anda harus mendapatkan output berikut:
2020-11-23 10: 31: 51.318 Info Namenode.NnstorageretentionManager: akan mempertahankan 1 gambar dengan txid> = 0 2020-11-23 10: 31: 51.323 info namenode.FSIMAGE: FSIMAGAVER CLEAN CHECKPOINT: TXID = 0 Saat bertemu shutdown. 2020-11-23 10: 31: 51.323 Info Namenode.Namenode: shutdown_msg: /********************************************* *******************_Msg: Mematikan namenode di Hadoop.tecadmin.net/127.0.1.1 *********************************************** ***********/
Setelah memformat namenode, jalankan perintah berikut untuk memulai kluster Hadoop:
start-dfs.SH Setelah HDFS dimulai dengan sukses, Anda harus mendapatkan output berikut:
Memulai namenode di [Hadoop.tecadmin.com] Hadoop.tecadmin.com: Peringatan: ditambahkan secara permanen 'Hadoop.tecadmin.com, fe80 :: 200: 2dff: fe3a: 26ca%eth0 '(ecdsa) ke daftar host yang dikenal. Memulai Datasodes Memulai Namenodes Sekunder [Hadoop.tecadmin.com]
Selanjutnya, mulailah layanan benang seperti yang ditunjukkan di bawah ini:
Mulai-Bukur.SH Anda harus mendapatkan output berikut:
Mulai ResourceManager Memulai Nodemanagers
Anda sekarang dapat memeriksa status semua layanan Hadoop menggunakan perintah JPS:
JPS Anda akan melihat semua layanan berjalan di output berikut:
18194 Namenode 18822 Nodemanager 17911 SecondaryNamenode 17720 DataDe 18669 Resourcemanager 19151 JPS
Langkah 7 - Sesuaikan Firewall
Hadoop sekarang mulai dan mendengarkan di port 9870 dan 8088. Selanjutnya, Anda harus mengizinkan port ini melalui firewall.
Jalankan perintah berikut untuk memungkinkan koneksi Hadoop melalui firewall:
firewall-cmd --permanent --add-port = 9870/tcpfirewall-cmd --permanent --add-port = 8088/tcp
Selanjutnya, muat ulang layanan firewalld untuk menerapkan perubahan:
firewall-cmd --eload Langkah 8 - Akses Hadoop Namenode dan Manajer Sumber Daya
Untuk mengakses namenode, buka browser web Anda dan kunjungi URL http: // Anda-server-IP: 9870. Anda harus melihat layar berikut:
http: // hadoop.tecadmin.NET: 9870
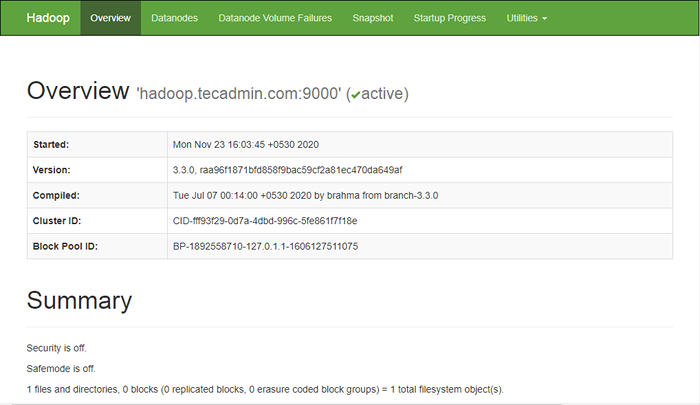
Untuk mengakses sumber daya mengelola, buka browser web Anda dan kunjungi URL http: // Anda-server-IP: 8088. Anda harus melihat layar berikut:
http: // hadoop.tecadmin.NET: 8088
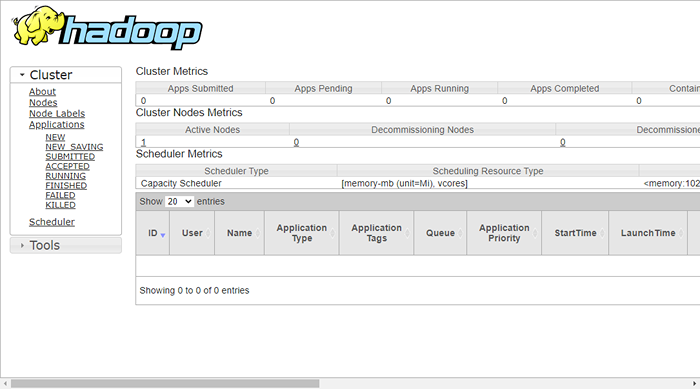
Langkah 9 - Verifikasi klaster Hadoop
Pada titik ini, cluster Hadoop diinstal dan dikonfigurasi. Selanjutnya, kami akan membuat beberapa direktori di sistem file HDFS untuk menguji hadoop.
Mari kita buat beberapa direktori di sistem file HDFS menggunakan perintah berikut:
HDFS DFS -MKDIR /TEST1HDFS DFS -MKDIR /LOG
Selanjutnya, jalankan perintah berikut untuk mencantumkan direktori di atas:
HDFS DFS -LS / Anda harus mendapatkan output berikut:
Ditemukan 3 item DRWXR-XR-X-HADOOP Supergroup 0 2020-11-23 10:56 /Log DRWXR-XR-X-HADOOP Supergroup 0 2020-11-23 10:51 /test1
Juga, letakkan beberapa file ke sistem file Hadoop. Sebagai contoh, menempatkan file log dari mesin host ke sistem file hadoop.
hdfs dfs -put/var/log/*/log/ Anda juga dapat memverifikasi file dan direktori di atas di antarmuka web Hadoop Namenode.
Buka antarmuka web namenode, klik utilitas => Jelajahi sistem file. Anda akan melihat direktori Anda yang telah Anda buat sebelumnya di layar berikut:
http: // hadoop.tecadmin.net: 9870/explorer.html
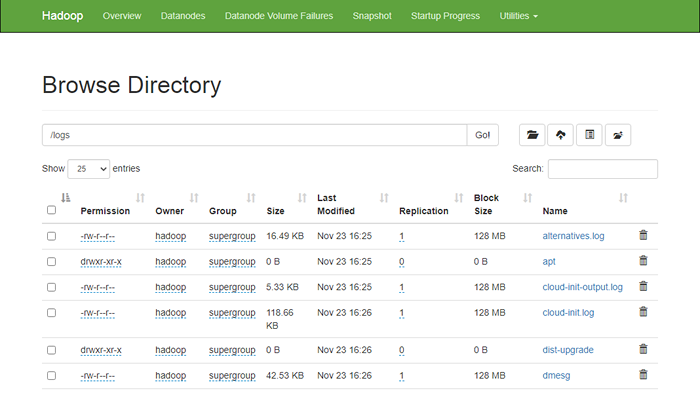
Langkah 10 - Stop Hadoop Cluster
Anda juga dapat menghentikan layanan namenode dan benang Hadoop kapan saja dengan menjalankan stop-dfs.SH Dan Berhenti-Buku.SH skrip sebagai pengguna Hadoop.
Untuk menghentikan layanan Hadoop Namenode, jalankan perintah berikut sebagai pengguna Hadoop:
stop-dfs.SH Untuk menghentikan layanan Hadoop Resource Manager, jalankan perintah berikut:
Berhenti-Buku.SH Kesimpulan
Tutorial ini menjelaskan kepada Anda tutorial langkah demi langkah untuk menginstal dan mengonfigurasi Hadoop di Ubuntu 20.04 Sistem Linux.